| Front page | | Contents | | Previous |
Reducing Uncertainty in LCI
Annex B. Terminology on uncertainty and statistical properties
Many different concepts are used to describe uncertainty. This annex describes the terms used in this document. When applicable, statistical terms are defined in accordance with ISO 3534.
Uncertainty is the general term we use to cover any distribution of data caused by either random variation or bias. Uncertainty expresses the general problem that an observed value can never be exactly reproduced, but when an adequate number of observations have been made, certain characteristic features of their distribution can be de scribed, such as mean and standard deviation.
Variation is the general term used for the random element of uncertainty. This is what is typically described in statistical terms as variance, spread, standard deviation etc., see definitions below. It is the randomness of the observations, which allows a statistical treatment, since this describes the probability distribution of the observations.
Bias is the skewness introduced into a distribution as a result of systematic (as opposed to random) errors in the observations, e.g. when the observations are made on a specific sub-set of a non-homogenous population.
Population is the total number of items under consideration, from which only a sample is typically observed.
Probability distribution is the function giving the probability that an observation will take a given value. The function is typically described in mathematical and/or graphical form, see also under normal distribution and lognormal distribution.
The mean or average value is the sum of the observed values divided by the number of observations.
The median ( ) is the value for which 50% of the distribution is smaller and 50% of the distribution is larger, also known as the 50% fractile. ) is the value for which 50% of the distribution is smaller and 50% of the distribution is larger, also known as the 50% fractile.
The mode is the value that has the largest probability within the distribution.
The error of an observation is the deviation of the observed value from the mean value, i.e the value of the observation minus the mean value.
Variance is a description of variation defined as the sum of the squares of the errors divided by the number of observation less 1.
The standard deviation (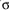 ) is the positive square root of the variance. ) is the positive square root of the variance.
The coefficient of variance (CV) is the standard deviation divided by the mean value.
The normal distribution is a specific probability distribution also known as Gaussian or bell-shaped often found in real life populations. The reason for this is its specific mathematical properties, namely that 1) any sum of normal distributions is itself a normal distribution, and 2) when enough non-normal distributed variables are added, the result is approximately normal distributed. This is called the “central limit theorem” (Stevenson & Coates 1997 and Krider 2001 give wonderful illustrations of this theorem). The convergence to the normal distribution is surprisingly fast. For example, the distribution of the sum of ten uniformly distributed random variables is already indistinguishable by eye from an exact normal distribution. Since many real life phenomena are caused by a large number of independent random effects, the central limit theorem explains why we so often find real life data to be approximately normally distributed. The normal distribution is a symmetrical distribution (as opposed to a skewed distribution, see the lognormal distribution), which implies that the mean, the median and the mode all appears at the same place (at the centre or top of the curve, see the figure). An interesting feature of the normal distribution is that 68% of the data lies within one standard deviation either side of the mean, 95% of the data lies with two standard deviations of the mean, and 99.7% of the data lies within three standard deviations of the mean. Thus, it is easy to compare confidence intervals and standard deviations.
A two-sided confidence interval is the central part of a distribution that lies between two values chosen so that it is certain that the interval includes a required percentage of the total population. For example, in a 95% confidence interval, you can be 100% confident that it includes 95% of the population, i.e. it excludes 2.5% of the population in both ends.
The lognormal distribution is a specific probability distribution where the natural logarithm of the observed values follow a normal distribution. The lognormal distribution is also common in real life populations. One reason for this is that many real life effects are multiplicative rather than additive, and in parallel to the central limit theorem for additive effects (see under the normal distribution), it can be shown that multiplicative effects will result in a lognormal distribution. Another reason is that real life populations typically cannot attain values below zero, and with a high variation this will result in a skewed distribution with a longer tail towards the higher values. The lognormal distribution is such a skewed distribution, although certainly not the only one. Because of its easy transformation into the normal distribution, it is often – and also in our analysis here - used out of convenience, as an approximation for other more complicated, skewed distributions. As for the normal distribution, the confidence intervals is related to the standard deviation, but for the lognormal distribution, this relation is multiplicative: 68% of the data lies in the interval / to , 95% of the data lies in the interval /2 to 2, and 99.7% of the data lies in the interval /3 to 3.
The range is the difference between the largest and the smallest observed value. Empirical data are often given as a range, expressed e.g. by a minimum and a maximum value. The range will increase with an increasing number of observations, since it becomes more likely that the range will cover the full population. For the normal distribution, the range is approximately 3, 4, and 5 times the standard deviation when the sample size is 10, 30, and 100, respectively. This relation can be used to calculate the standard deviation when the range is given. Life cycle data often result from a small number of observations, so it is reasonable to use the factor 3 when the number of observations is unknown.
Plus/minus (+/-) is a popular way of expressing uncertainty. However, it is not always clear what is the intended meaning, especially when a skewed distribution is described. In this text, we use the +/- to describe a range, generally with the above assumption that we thereby cover 3 times the standard deviation.
Factor (e.g. “factor 2”, “factor 5” or “factor 10”; the latter being identical to “an order of magnitude”) is another popular way of expressing uncertainty. Compared to “plus/minus”, the factor may indicate a skewness. Consider for example 20+/-50%, which is equal to the interval 10-30, while a “factor 2” on 20 denotes the interval 10-40, i.e. a skewness resembling that of a lognormal distribution. An order of magnitude on 20 denotes the interval 2-200, which is very difficult to describe by a “plus/minus” notation. However, the concepts of factor and order of magnitude are used ambiguously. When used without indication of mean value, they may describe the size of a range, in which case an order of magnitude may denote e.g. the interval 2-20 or 20-200. In this text, we use the concepts in the former sense, i.e. as a factor on the mean value.
| Front page | | Contents | | Previous | | Top |
|