|
Kortlægning af diffus jordforurening i byområder. Delrapport 3 Bilag C
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 Introduktion | |
| 1.1 | Deskriptivt |
| 1.2 | Geografisk korrelation af data |
| 2 Software | |
1. Introduktion
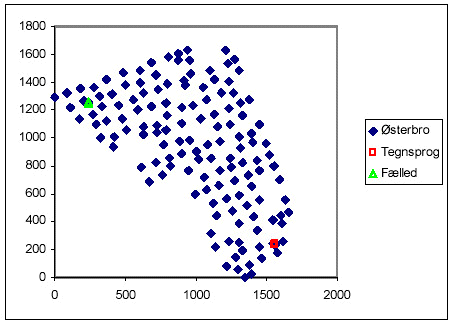
Datasættet er opdelt i tre grupper:
- "Østerbro": 138 positioner på Østerbro
- "Tegnsprog": 24 positioner, Center for tegnsprog, tæt på punkterne B147 og B148 fra "Østerbro"
- "Fælled" : 9 positioner, Fælledparken, tæt på punkterne B11 og B12 fra "Østerbro"
"Østerbro" datasættet er tidligere analyseret i bilag B. De tre datasæt vil i det følgende blive analyseret hver for sig og som et samlet datasæt. I datasæt "Tegnsprog" og datasæt "Fælled" er der gentagne målinger på de enkelte prøver.
1.1 Deskriptivt Statistik
Det ofte ses ved analyse af jordforureningsdata at en logaritme transformation af værdierne gør at data bliver approksimativt normalfordelte. Der er derfor i nedenstående Tabel 1 angivet deskriptive størrelser for både de målte værdier samt de logaritmerede værdier (den naturlige logaritme).
Tabel 1
Deskriptive statistiske størrelser
Descriptive statistical values
|
Østerbro |
Tegnsprog |
Fælled |
Loge Østerbro |
Loge |
Loge |
Minimum |
9,00 |
134,0 |
30,0 |
2,20 |
4,90 |
3,40 |
25% Fraktil |
32,0 |
186,5 |
40,8 |
3,47 |
5,23 |
3,71 |
Middelværdi (gennemsnit) |
88,6 |
238,6 |
43,1 |
4,08 |
5,44 |
3,75 |
Median |
65,0 |
219,0 |
43,0 |
4,17 |
5,38 |
3,76 |
75% Fraktil |
120 |
294,5 |
47,0 |
4,79 |
5,69 |
3,85 |
Maksimum |
740 |
376 |
57,0 |
6,61 |
5,92 |
4,04 |
Standard afvigelse (spredning) |
95,5 |
65.6 |
6,30 |
0,904 |
0.28 |
0,15 |
Antal datapunkter |
138 |
24 |
9 |
138 |
24 |
9 |
Median er lav i forhold til middelværdien for "Østerbro" og "Tegnsprog", hvilket indikerer asymmetrisk fordeling af værdierne med en lang højre (høje værdier) hale på fordelingen. Dette betyder at en transformation bør overvejes for disse datasæt. I den samlede analyse vil alle data blive transformeret og dermed mindske betydningen af enkelte meget høje koncentrationer.
Baseret på de deskriptive størrelser i forrige afsnit er i Figur 1 vist histogrammet (Densiteten) for alle tre datasæt Loge(Bly). Endvidere er den estimerede densitet plottet som en sort kurve. Histogrammer afviger ikke meget fra en sædvanlig "klokkeformet" normalfordeling. Både "Fælled" og "Tegnsprog" er jvf Tabel 1 fuldt indeholdt i histogrammet og antager ikke ekstreme værdier.
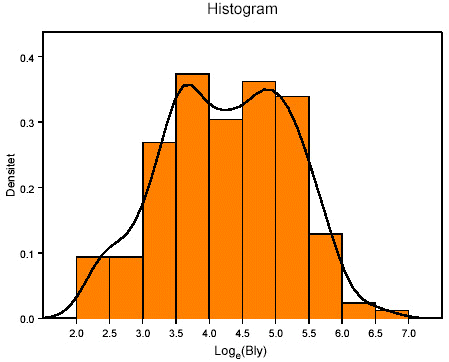
Figur 1
Histogram (Densiteten) for Loge(Bly). Den estimerede densitet er plottet
som en sort kurve. De afbildede histogrammer afhænger af valget af intervalbredde og
kurven af estimationsmetoden.
Histogram (Density) for Loge(lead). The estimated density is plotted as a black curve. The illustrated histogram depends on the choice of width of interval and on the estimation method.
1.2 Geografisk korrelation af data
Positionerne for "Fælled" og "Tegnsprog" er plottet nedenstående. Det er valgt at inddele data i henholdsvis 3 og 5 grupper (a,…,e) udfra deres placering. Først vurderes de enkelte grupper i forhold til hinanden. Dette er vist visuelt i box-plottene under (x,y-plottene). Den blå boks er "Inner-Quartile Range" dvs fra 25-75% kvartilen. Stregerne markerer range af data. Der ses forskelle for "Tegnsprog" men ikke for "Fælledparken".
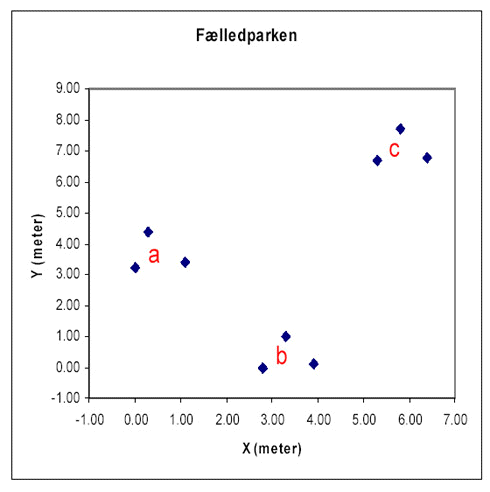
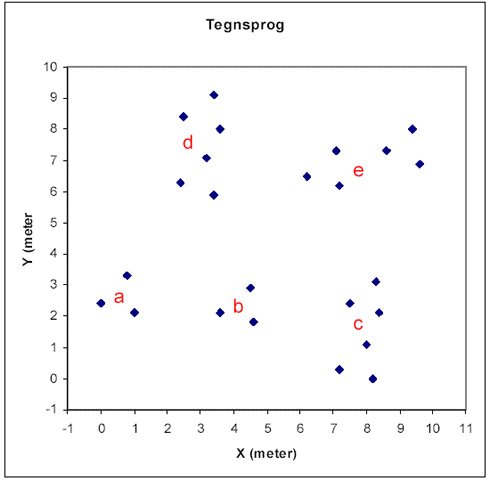
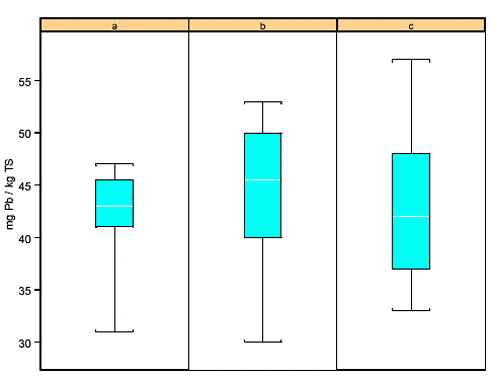
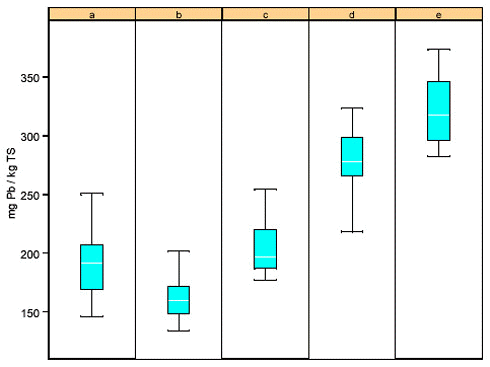
Disse resultater kan ligeledes vurderes i en variansanalyse, her foretaget på der ikke-transformerede data. Den totale variation kan splittes op i 3 niveauer, hvor Niveau 1 er variansen af gruppemiddel i forhold til totalmiddel, Niveau 2 er variansen af middelværdien for de gentagne målinger i forhold til gruppemiddel og Niveau 3 er residualvariationen fra enkeltmålinger i forhold til middel af gentagne observationer.
Lokalitet \ Varians |
Niveau 1 |
Niveau 2 |
Residual |
Tegnsprog |
4203 |
101 |
725 |
Fælled |
<0.01 |
<0.01 |
36 |
Disse resultater antyder at small-variationen (som funktion af afstanden) ikke er ens overalt, hvilket ikke er overraskende men heller ikke opmuntrende idet dette ofte antages i geostatistiske analyser.
For "Tegnsprog" er der forskel på bly-niveauet i de fem grupper (a,…,e) men ikke forskel på punkterne i de enkelte grupper. Der forventes dermed at være
For "Fælled" er der ikke forskel på de tre grupper (a,b,c) og dermed er der ingen grund til at lave en spatiel analyse af disse data.Variogrammet for "Tegnsprog er vist nedenstående
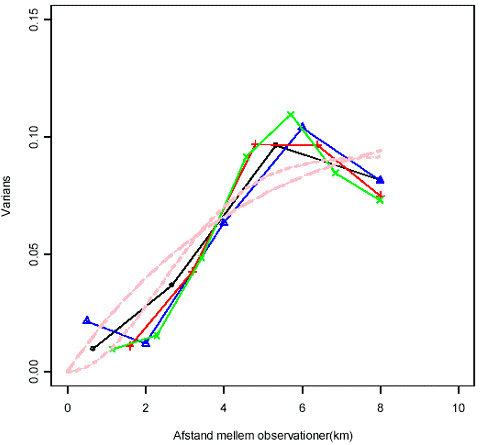
Det er tydeligt at variansen er afhængig af afstanden, det er dog ikke helt tydeligt om range er nået. Der er fitte to variogrammer hvilket resulterede i parameter estimaterne givet i nedenstående tabel.
|
Nugget |
Sill |
Range |
Exponentiel |
0 |
0.12 |
4,71 |
Gausisk |
0 |
0.09 |
3,32 |
Maksimum Likelihood |
0,0076 |
0,0569 |
3,72 |
Den sorte kurve er den maksimale afstand sat til 8m km med 4 intervaller. Den blå kurve er den maksimale afstand sat til 8 m med 5 intervaller. Den røde kurve er den maksimale afstand sat til 8 m med 6 intervaller. Den grønne kurve er den maksimale afstand sat til 8 m med 8 intervaller.
Det bemærkes at det visuelle indtryk af nugget effekten ændres ved forskelligt valg af antal punkter. Vælges en af disse værdier arbitrært vil det få meget stor indflydelse på usikkerheden på estimationen.
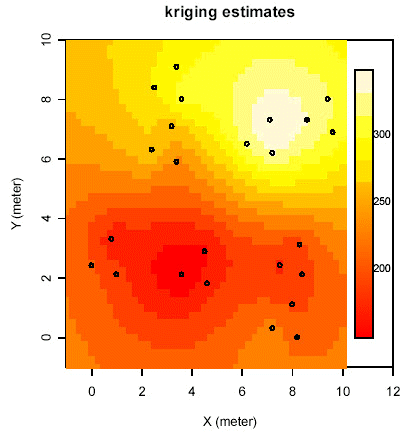
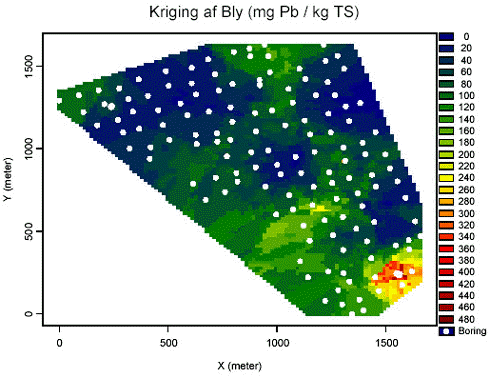
Kriging med anvendelse af maximum likelihood estimatet er vist nedenstående
De tre datasæt er vist nedenstående, målet med behandling af de tre datasæt sammen er at udnytte "Tegnsprog" og "Fælled" til at beskrive beskrivet small-scale variationen.
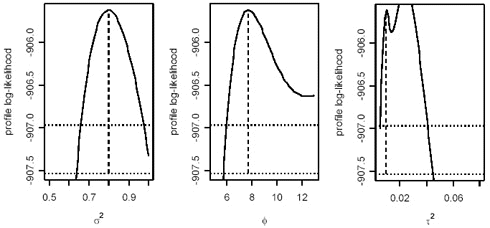
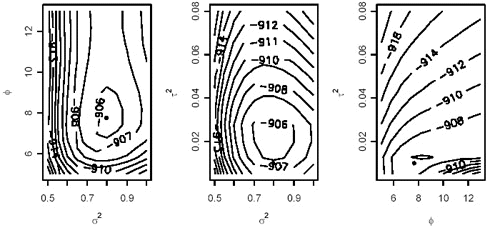
Maksimum likelihood af alle data er beskrevet i nedenstående tabel
|
Nugget |
Partial Sill |
Sill |
Range |
LogLikelihood |
Mean (logeBly) |
Maksimum likelihood |
0,0096 |
0,798 |
0,807 |
7,72 |
-905,6155 |
4,11 |
2. Software
Til analyserne er anvendt: http://www.maths.lancs.ac.uk/~ribeiro/geoR.html