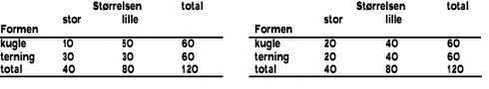Vurdering af konsekvenser af forslaget til nyt badevandsdirektiv fra EU, dateret 24.10.2002Bilag A Statistiske antagelser og metoder
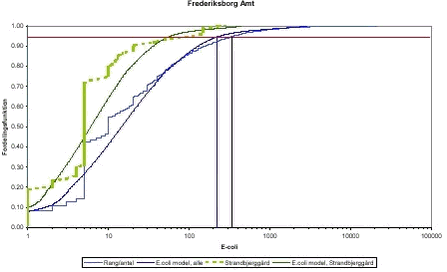
Antagelse om log-normal fordelte prøver Det antages almindeligvis, at indhold af fækale colibakterier i badevandsprøver er log-normal fordelte. Mange undersøgelser har da også godtgjort at det er en rimelig antagelse. Med de mange målinger, herunder mange målinger under detektionsgrænsen, kan antagelsen vise sig at være upræcis. For at teste hypotesen om log-normal fordeling er alle prøver fra Frederiksborg Amt optegnet som en fordelingsfunktion og den tilsvarende fordeling optegnet. Resultatet er vist i Figur 8. Af figuren fremgår, at der er en tendens til, at den faktiske fordeling er endnu mere højre-skæv end en log-normal fordeling. Det betyder, at antagelsen om log-normal fordelte data betyder, at modellen forudsiger lavere forekomster af fækale colibakterier i maksimalt 5% af tiden end der faktisk forekommer. En stor del af målingerne i Figur 8 er under detektionsgrænsen. Disse er tildelt en værdi svarende til det halve af detektionsgrænsen. Derfor er der en stor mængde prøver med 5/100 ml, svarende til en detektionsgrænse på 10/100 ml. Reelt vil disse prøver have fra 0-9/100 ml og ikke præcist de angivne 5/100 ml. Hvis disse (ikke-)målinger i stedet fik tildelt værdien 0,1 cfu/100 ml ville resultatet være, at den faktiske fordeling var mindre skæv end log-normal fordeling, svarende til, at modellen forudsiger højere forekomster i maksimalt 5% af tiden end der faktisk forekommer. På baggrund af de målte forekomster af fækale colibakterier i Frederiksborg Amt kan det derfor konkluderes, at log-normal fordelingen er rimelig at anvende.
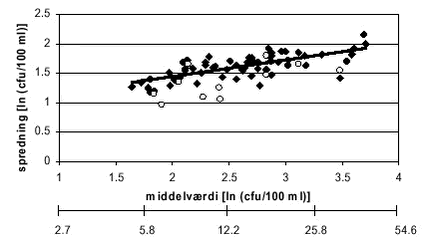
Strandbjerggård er en badevandsstation på den nordvestlige side af Frederiksborg Amt. Målingerne fra denne station og den tilsvarende model er vist i Figur 8. Det fremgår af figuren Under antagelse af, at log-normal fordelingen er rimelig kan man samle informationen om alle prøver ved en badevandsstation i to parametre, middelværdi og spredning. Disse parametre kunne tænkes at være korrelerede. Dette er testet i Figur 9. Det ses, at der er en tydelig sammenhæng mellem middelværdien og spredning og at ferskvandsstationerne generelt har lidt lavere spredning end saltvandsstationerne.
Simpelt test for korrelation mellemvariable, kontingenstabeller En kontingenstabel er en tabel med (mindst 2) variable, der kan være i flere tilstande. Derefter tæller man, hvor mange prøver, der er i hver tilstand. Derefter kan man afprøve en hypotese om, hvorvidt de to variable er korrelerede. I tabel 32 er et lille eksempel illustreret som skulle hjælpe på forståelsen. Det fordelagtige i denne test er, at hypotesen er uafhængig af variablenes opførsel i øvrigt, herunder hvilken fordeling variablene har. Den underliggende teori og teststørrelser er beskrevet i diverse lærebøger, f.eks. Conradsen (1995). Antagelse om uændret badevandskvalitet de seneste 7 år Der udtages som regel 10 prøver pr. station pr. år, men for nogle stationer udtages kun 5 prøver pr. år. Det er et spinkelt grundlag for bestemmelse af ekstreme værdier. Jo flere prøver der udtages, desto bedre grundlag er der for de statistiske vurderinger og dermed sikkerhed i vurderingen. Derfor er det i nogle tilfælde valgt at summere alle 7 års målinger frem for at foretage vurderingen af badevandsstationerne år for år. For at kunne gøre dette bør det checkes, at der ikke er væsentlige forskelle mellem badevandskvaliteten de forskellige år der summeres. Dette gøres ved hjælp af kontingenstabeller. For at teste om der er forskel mellem forskellige år opstilles en kontingenstabel med følgende variable: årstal og antal fækale colibakterier. Målet med analysen er at fastslå, hvorvidt en sådan kontingenstabel er tæt på tabellen til højre i tabel 32. Hvis det er tilfældet kan man konkludere, at det er rimeligt at summere målinger fra forskellige år, fordi forskellene mellem de enkelte år er uden betydning. Tilstandene for fækale colibakterier er opdeles i to: højt (> 500/100 ml) og lavt (maximalt 500/100 ml). Tilsvarende er årstal opdelt i tre tilstande, der hver består af 2-3 års målinger. Resultatet er vist i tabel 33
Det ses af tabel 33, at der er i 1995-1998 forventes færre prøver med fækale colibakterier over 500/100 ml end der faktisk forekommer og omvendt i årene 1999-2001. Det svarer til, at der er en tendens til, at badevandskvaliteten bliver bedre i løbet af årene. Der er dog ikke stor forskel mellem de forventede værdier og de faktiske målinger. Det statistiske test accepterer da også en hypotese om, at der ikke er nogen korrelation mellem de to variable. Derfor antages det i det efterfølgende, at alle prøver fra samme badevandsstation tilhører samme statistiske fordeling på trods af, at der i målingerne er en tendens til, at badevandskvaliteten bliver bedre.
Opbygning af empiriske lineære statistiske modeller Valg af modeltype Der opbygges empiriske statistiske modeller af følgende type:
hvor ε tilhører en normalfordeling med middelværdi 0 og varians σ2. På baggrund af målinger af variablen Kvalitet på stationen og variablene variabel1, variabeln estimeres så de optimale parameterværdier for α1, , αn og σ2. En sådan model benævnes en generel lineær model og er et almindeligt værktøj til at søge at beskrive forskellige variables betydning for den variabel, kvaliteten, som man ønsker at modellere. For hver faktor kan der defineres flere variable. For renseanlæg er således defineret 4 variable:
Hver af disse variable testes separat for at sikre at modellen har den bedst mulige evne til at beskrive variationen i kvaliteten. Modellen opstilles først på alle de variable, der kan tænkes at have betydning. På baggrund af denne totale model undersøges det, om en mere simpel model giver en lige så god beskrivelse af kvaliteten som den større model. En lige så god beskrivelse betyder i denne sammenhæng, at den estimerede varians ikke vokser væsentligt. Hvis ikke den estimerede varians vokser væsentligt af ikke at inddrage en variabel kan man udelade den fordi den så ikke bidrager til at beskrive en variation som ikke kan beskrives ved hjælp af de øvrige variable. Den variabel som bidrager mindst til forklaringen af variationen af kvaliteten slettes derefter af modellen. Dernæst undersøges den nye, reducerede, model for, om den kan reduceres yderligere uden at den estimerede varians øges væsentligt. På den måde undersøges mere og mere simple modeller indtil modellen kun består af variable, der bidrager væsentligt til at forklare variationen af kvaliteten. Slutteligt undersøges denne model ved at inddrage alle variablene i den fulde model en ad gangen. Dermed sikres, at der ikke undervejs er sket en væsentlig tab af information, der kan bidrage til at forklare variationen af kvaliteten. Metoden benævnes stepwise regression. For en mere grundlæggende introduktion, herunder til en definition af en væsentlig forøgelse af variansen, henvises til den statistiske faglitteratur. Det bemærkes, at selve værdien af de enkelte parametre, α1, , αn, ikke kan tolkes som et udtryk for hvor vigtig en variabel er. Valg af den optimale model Valg af den optimale model vil altid være et subjektivt valg afhængigt af den konkrete problemstilling. Generelt reduceres modeller ned, således at alle de uafhængige variable er signifikante. At være signifikant betyder i den sammenhæng, at der er lille sandsynlighed for, at korrelationen mellem kvaliteten og den pågældende variabel er tilfældig og uden underliggende årsager. I modelopbygningen anvendes generelt en sandsynlighed på 5 % for at afvise, at korrelationen er tilfældig. I et enkelt tilfælde er det dog valgt at inddrage en variabel med en sandsynlighed på 6 % for tilfældig variation. Inddragelse af en ekstra variabel vil per definition medføre en lidt bedre model målt i evnen til at forklare variationen i kontrolstørrelsen. Ved brug af f.eks. AIC (Akaike‘s informationskriterium) kan "prisen" for en ekstra variabel afvejes mod "prisen" for en lidt dårligere beskrivelse. Det vil i nogle tilfælde medføre, at også statistisk signifikante variable ikke inddrages i den endelige model. |