Stofkoncentrationer i regnbetingede udledninger fra fællessystemer
4. Analyse af korrelationsstruktur
4.1 Forklaringsgrad for hver variabel og hvert opland
4.2 Korrelationsstruktur for variable på tværs af oplande
4.3 Samvariation mellem forklarende variable
4.4 Generel lineær model
Forklarende variable
For de fem af oplandene er der flere mulige forklarende variable, som kan bruges til at beskrive variationerne af HMK. De primære variable er baseret på tid siden sidste regnhændelse samt karakteristika ved såvel regn som afstrømning. I tabel 4.1 er vist en oversigt over alle de forklarende variable, der er blevet benyttet i beregningerne af korrelationer. Som omtalt i kapitel 2 er det ikke lykkedes at etablere data fra Odinsvej til brug for denne del af undersøgelsen.
Tabel 4.1 Se her!
Oversigt over målinger, der indgår i korrelationsundersøgelsen. Hændelser på
under ca. 1 mm er frasorteret. Odinsvej indgår ikke i datamaterialet. Forkortelse for de
forklarende variable er angivet i parentes.
Formål
Den primære formål med at undersøge korrelationerne er at undersøge og i givet fald identificere, hvilke variable fra tabel 4.1 der bedst beskriver variationen i hændelsesmiddelkoncentrationen. Disse variable kan så benyttes til at søge efter hvilke underliggende processer der styrer de observerede korrelationer.
Variation mellem oplande
Fordelingerne for de enkelte oplande kan antages at være ens for P, N og COD uden forklarende variable for de fem oplande. For SS er der en systematisk variation mellem oplande, der bør medtages. For P, N og COD kan inddragelse af forklarende variable medføre, at variationen mellem oplande bliver signifikant, fordi den residuale variation bliver mindre. Dette gælder specielt for P, hvor der kun er 10% sandsynlighed for, at oplandene er ens.
4.1 Forklaringsgrad for hver variabel og hvert opland
Korrelationerne undersøges ved at opbygge to typer af regressionsmodeller på baggrund af data. Regressionsmodellerne benyttes, fordi de giver det bedste billede af, hvor god en variabel er til at beskrive variationen for en bestemt stoftype. I den første undersøgelse opbygges modeller af følgende type for hvert opland og hver stoftype separat:
(4.1) |
hvor E antages at være normalfordelt med midelværdi 0 og spredning s . m , a og s er parametre der estimeres. Forklaringsgraden, R2, beregnes som den reduktion af variansen der sker i forhold til ikke at lade variablen indgå i modellen (svarende til a = 0). Forklaringsgraden ligger mellem 0 og 1 og en høj værdi for en given variabel betyder altså, at denne variabel er velegnet til at beskrive variationen i HMK. I tabel 4.2 er angivet de variable, som ved en regressionsmodel af typen (4.1) giver forklaringsgrader på mindst 20%. Forklaringsgraden er valgt så lavt fordi formålet primært er at screene datamaterialet for mulige forklarende variable.
De variable, der generelt er nævnt flest gange i tabel 4.2 er ivar, afvol, qvar og ttoer, men også ivol, igns og qmax er nævnt flere gange. Derimod tyder det på, at i10 og qgns er uegnede til at indgå i en model. Generelt giver de utransformerede variable højere forklaringsgrader end de log-transformerede.
4.2 Korrelationsstruktur for variable på tværs af oplande
De enkelte forklarende variable kan også testes samtidigt på alle oplande ved at opbygge en model af typen
(4.2) |
hvor OPLAND og E er stokastiske variable og a 1 og a 2 er parametre, som skal estimeres sammen med spredningerne på OPLAND og E, hhv. s OPL og s E. På den måde kan den enkelte variabel testes på tværs af oplandene, under forudsætning af, at variationen mellem oplande kan beskrives som en konstant forskel i niveauet.
Forklaringsgraderne for modeller af typen (4.2) ligger generelt mellem 10 og 50%. For disse modeller er det imidlertid også vigtigt at teste, hvilken af variablene der har størst betydning. Man kunne f.eks. tænke sig, at det var variationen mellem oplande, der gjorde, at en model havde en høj forklaringsgrad. Derfor skal nu både hele modellen testes, men også de individuelle bidrag. Det gøres ved at beregne, hvor stor sandsynligheden er for, at såvel hele modellen som de enkelte bidrag er signifikante, dvs. om forklaringsgraden er stor nok til at berettige til at parameteren bliver inddraget. Disse sandsynligheder er angivet i tabel 4.3. Sandsynligheden vil have værdier mellem 0 og 1, således at en lav værdi indikerer stor betydning. I statistisk litteratur benyttes ofte en grænse på 5%, således at værdier under 5% indikerer, at denne variabel bør indgå i modellen.
| Opland | Stoftype | Forklaringsgrad > 0.20 |
| Vestre Paradisvej | log(SS) | ivar, log(ivar),i10, log(i10),qvar, log(qvar),ttoer |
| log(P) | ivar, log(ivar), igns, log(igns), qvar, log(qvar), ttoer | |
| log(N) | ivar, log(ivar), igns, log(afvol), qvar, log(qvar), ttoer | |
| log(COD) | log(qvar), ttoer | |
| Cedervænget | log(SS) | ivar, log(ivar), i10, igns, log(igns), qmax, log(ttoer) |
| log(P) | afvol, qvar, log(qvar), log(ttoer) | |
| log(N) | log(ivar), ttoer, log(ttoer) | |
| log(COD) | log(ivar), igns, log(igns), ttoer, log(ttoer) | |
| Soldalen | log(P) | |
| log(N) | ||
| log(COD | ivol, log(ivol), afvol, log(afvol), qgns, log(qgns) | |
| Vissing | log(SS) | ivar, log(ivar), ttoer |
| log(P) | ||
| log(N) | ttoer | |
| log(COD) | ivar, log(ivar), afvol, log(afvol) | |
| Hasseris | log(SS) | log(ivol), ivar, log(ivar), log(afvol), qvar, log(qvar), ttoer, log(ttoer) |
| log(P) | ivol, log(ivol), ivar, log(ivar), afvol, log(afvol), qmax, log(qmax), qvar, log(qvar), qgns, log(qgns), ttoer, log(ttoer) | |
| log(N) | ivol, log(ivol), ivar, log(ivar), afvol, log(afvol), qmax, qvar, log(qvar), qgns, ttoer, log(ttoer) | |
| log(COD) | ivol, log(ivol), ivar, log(ivar), afvol, log(afvol), qmax, log(qmax), qvar, log(qvar), qgns, log(qgns, ttoer, log(ttoer) |
Tabel 4.2
Oversigt over hvilke variable der giver en forklaringsgrad på mere end 20% for
stoftypen. Der er korreleret til alle forklarende variable angivet i tabel 4.1, såvel
utransformerede som log-transformerede.
Det fremgår at tabel 4.3 at de variable, der bedst beskriver variationen for de enkelte stoftyper er ivol, ivar, igns, afvol, qvar og ttoer. I alle tilfælde er det de utransformerede variable, der giver den bedste forklaringsgrad.
| Forklarende variabel | Stoftype | Hele modellen | Opland | Utrans- formeret | Log- transformeret |
| ivol | log(SS) | 0.00 | 0.00 | 0.00 | 0.36 |
| log(P) | 0.00 | 0.00 | 0.00 | 0.86 | |
| log(N) | 0.00 | 0.09 | 0.00 | 0.67 | |
| log(COD) | 0.00 | 0.00 | 0.00 | 0.55 | |
| ivar | log(SS) | 0.00 | 0.00 | 0.00 | 0.02 |
| log(P) | 0.00 | 0.00 | 0.00 | 0.32 | |
| log(N) | 0.00 | 0.06 | 0.00 | 0.13 | |
| log(COD) | 0.00 | 0.00 | 0.00 | 0.15 | |
| i10 | log(SS) | 0.00 | 0.00 | 0.02 | 0.42 |
| log(P) | 0.11 | 0.04 | 0.35 | 0.62 | |
| log(N) | 0.48 | 0.21 | 0.69 | 0.69 | |
| log(COD) | 0.86 | 0.61 | 0.69 | 0.76 | |
| igns | log(SS) | 0.00 | 0.00 | 0.00 | 0.38 |
| log(P) | 0.00 | 0.00 | 0.32 | 0.18 | |
| log(N) | 0.04 | 0.11 | 0.04 | 0.14 | |
| log(COD) | 0.60 | 0.00 | 0.15 | 0.68 | |
| afvol | log(SS) | 0.00 | 0.00 | 0.00 | 0.10 |
| log(P) | 0.00 | 0.00 | 0.00 | 0.13 | |
| log(N) | 0.01 | 0.08 | 0.00 | 0.39 | |
| log(COD) | 0.00 | 0.00 | 0.00 | 0.08 | |
| qmax | log(SS) | 0.00 | 0.00 | 0.32 | 0.86 |
| log(P) | 0.00 | 0.00 | 0.06 | 0.95 | |
| log(N) | 0.23 | 0.10 | 0.47 | 0.73 | |
| log(COD) | 0.00 | 0.00 | 0.10 | 0.60 | |
| qvar | log(SS) | 0.00 | 0.00 | 0.00 | 0.21 |
| log(P) | 0.00 | 0.00 | 0.00 | 0.05 | |
| log(N) | 0.00 | 0.05 | 0.00 | 0.05 | |
| log(COD) | 0.00 | 0.00 | 0.05 | 0.09 | |
| qgns | log(SS) | 0.00 | 0.00 | 0.60 | 0.33 |
| log(P) | 0.00 | 0.00 | 0.24 | 0.19 | |
| log(N) | 0.09 | 0.09 | 0.24 | 0.19 | |
| log(COD) | 0.00 | 0.00 | 0.34 | 0.18 | |
ttoer |
log(SS) | 0.00 | 0.00 | 0.00 | 0.13 |
| log(P) | 0.00 | 0.00 | 0.00 | 0.36 | |
| log(N) | 0.00 | 0.04 | 0.00 | 0.69 | |
| log(COD) | 0.00 | 0.00 | 0.00 | 0.17 |
Tabel 4.3
Sandsynligheden for at en modellen som helhed samt de enkelte komponenter af en model
svarende til ligning (4.2) er signifikante. Variable med fed skrift er bedst til at
beskrive variationen i HMK på tværs af oplande.
4.3 Samvariation mellem forklarende variable
De to typer af regressionsmodeller peger på de samme variable til at beskrive variationen i HMK, ivol, ivar, igns, afvol og ttoer. Disse variable er imidlertid internt korrelerede, dvs. de indeholder delvist den samme information.
Principale komponenter
Den interne korrelationsstruktur mellem de fem variable kan undersøges ved hjælp af den statistiske metode principale komponenter. Den teoretiske baggrund og tolkningen af de numeriske resultater er beskrevet i Morrison (1967). Analysen viser, at 56% af den samlede variation i de fem variable kan forklares ved samvariation mellem ivol, ivar og afvol. Yderligere 22% skyldes samvariation mellem igns og ttoer. Den resterende variation skyldes stort set, at ttoer afviger fra de øvrige variable.
4.4 Generel lineær model
Da ivol og afvol minder meget om hinanden vil kun ivol blive benyttet af hensyn til generaliserbarheden. Der er dermed 4 variable, der kan blive brugt under opbygningen af en generel lineær model: ivol, ivar, igns og ttoer. Modellen er dermed af typen
![]()
(4.3)
hvor signaturerne er som tidligere defineret. Det testes nu for hver stoftype, hvilke parametre, der er signifikante og bedst beskriver variationen. De endelige modeller og parameterestimater er vist i tabel 4.4.
R2 |
m |
a 1 |
a 3 |
a 4 |
s OPL |
s E |
|
| Modeller incl. Hasseris | |||||||
| log(SS) | 0,66 |
2,36 |
-2,88 |
0,11 |
7,16 |
1,14 |
0,25 |
| log(P) | 0,52 |
0,49 |
-3,04 |
- |
8,14 |
0,77 |
0,27 |
| log(N) | 0,48 |
1,07 |
-2,94 |
- |
8,87 |
0,48 |
0,27 |
| log(COD) | 0,48 |
2,35 |
-2,97 |
- |
9,57 |
0,93 |
0,33 |
| Modeller excl. Hasseris | |||||||
| log(SS) | 0,51 |
2,78 |
-3,11 |
0,11 |
5,94 |
0,80 |
0,26 |
| log(P) | 0,34 |
0,38 |
-2,15 |
- |
8,44 |
0,49 |
0,26 |
| log(N) | 0,29 |
1,00 |
-1,96 |
- |
10,0 |
- |
0,27 |
| log(COD) | 0,21 |
2,19 |
-2,02 |
- |
11,2 |
- |
0,34 |
Tabel 4.4
Parameterestimater for generel lineær model. Modellerne og alle de parametre, der
indgår, er alle signifikante på et niveau mindre end 5%. Regnvoluminet, og dermeda 2, indgår ikke i modellerne, da denne variabel ikke er
signifikant.
Der er opstillet en tilsvarende model baseret på afstrømningens volumen:
(4.4) |
Denne model har samme forklaringsgrad som modellen vist i formel (4.3) for P, N og COD. For SS er modellen lidt dårligere til at forklare variationen i HMK. Der er mindre forskelle på den relative betydning af parametre, men med lidt ændret betydning.
Man kan tolke betydningen af regnens karakteristika som et mindstemål for betydningen af variationen under hændelsen og betydningen af den forudgående tørvejrsperiode som et mindstemål for variation mellem hændelser. Der er tale om mindstemål, fordi modellerne i formlerne (4.3) og (4.4) ikke afspejler de fysiske processer, som foregår mellem og under regn. Den relative betydning er vist på figur 4.1.
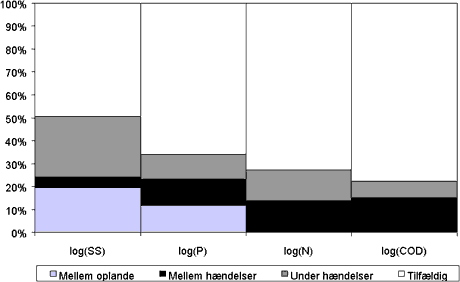
Figur 4.1
Forklaringsgraden af HMK-værdier for modellen beskrevet i formel (4.3). Den relative
betydning af de enkelte komponenter i modellen er angivet.
Alternativ modelformulering
Den konstruerede model svarer til, at der bliver ved med at blive opbygget sedimenter i tørvejrsperioder, og at der bliver ved med at blive fjernet sedimenter mv. under regn. En mere realistisk model vil være at modellere opbygning og fjernelse som 1. ordens processer, hvorved der vil ske en eksponentiel vækst til en givet mængde sedimenter i tørvejr og tilsvarende blive fjernet til et givet koncentrationsniveau under regn.
Residualanalyse
Der er lavet simple analyser af residualerne ved at plotte residualerne mod regressorerne. Der er ingen systematik i disse plots, der dog indikerer, at der for alle modellerne kun er et begrænset antal observationer med høj forudgående tørvejrsperiode og med lange varigheder.
Hasseris
Generelt har modellerne hvor Hasseris indgår en bedre forklaringsgrad. Det medfører dog, at spredningen mellem oplande øges kraftigt, hvorved prediktion til et nyt opland (uden målinger) vil blive mere usikker. Derfor diskuteres i det følgende kun modeller, hvor data fra Hasseris ikke indgår.
Variation internt i hændelser
Lang regnvarighed medfører mindre HMK og at lang forudgående tørvejrsperiode medfører højere HMK. Dette indikerer, at koncentrationsforløbet under hændelsen er som skitseret på figur 1.1, altså en generel tendens til faldende koncentration internt i hændelsen. Den tilfældige variation af HMK mindskes ved opbygningen af modellen, men ikke meget.
SS
SS har en rimelig forklaringsgrad, men variationen mellem oplande er stor. Selv om den residuale varians er halveret vil man ved prediktion af HMK for enkelte hændelser i et nyt og ukendt opland stadig beregne større varianser ved brug af modellen end uden pga. den store varians mellem oplande. Det anbefales derfor ikke at benytte modellen.
P
For P accepteres en hypotese om at variationen mellem oplande er uden betydning inden opbygningen af en model med forklarende variable. De forklarende variable mindsker den tilfældige variation således at der kan erkendes en forskel mellem oplandene. Variationen mellem oplandene er af en størrelsesorden, der vil medføre, at prediktion af HMK for en given hændelse i et ukendt opland vil være mere usikker ved brug af modellen end uden. Det anbefales derfor ikke at bruge modellen.
COD
N
Fordelingen af HMK for COD og N udviser ingen tegn på signifikante variationer mellem oplande, hverken før eller efter opbygning af modellen. Dermed kan den viste model benyttes til at beskrive variationen af HMK af N og COD i ukendte oplande. Forklaringsgraden er dog så ringe, at man må betvivle fordelen heraf.
|
|