|
Rapport om Vejledende liste til selvklassificering af farlige stoffer 2. Teknisk beskrivelse af listens tilblivelse og de anvendte QSAR modeller2.1 IndledningIndenfor et fagområde, der udvikler sig så hurtigt, som QSAR-området gør i dag, fremkommer der hele tiden bedre modeller, bedre valideringer og modeller for flere effekter – og følgelig opstår der aldrig det "rette" tidspunkt til at udgive vejledende klassificeringer baseret på QSAR forudsigelser. Der er dog i dag opsamlet betydelig information, som vurderes at kunne være til hjælp i den ellers vanskelige opgave, det er at vurdere farlige egenskaber for mange tusinde ikke-testede kemiske stoffer. Denne viden vil også kunne bidrage i planlægningen af fremtidige teststrategier, så indsatsen kan målrettes til de områder, hvor det er allermest nødvendigt. 2.1.1 SAR / QSARTeorien om at kemiske stoffer med lignende strukturer vil have lignende egenskaber er ikke ny. Allerede i 1890’erne blev det eksempelvis opdaget, at den bedøvende (narkotiske) virkning af kemiske stoffer over for akvatiske organismer var relateret til deres forhold mellem opløseligheden i henholdsvis olie og vand. Denne sammenhæng førte til brugen af log Kow (oktanol/vand fordelingskoefficienten) til forudsigelse af denne effekt. I dag er det velkendt, at alle kemiske stoffer vil udvise en minimums- eller "basal" narkotisk effekt, som er relateret til deres absorption i cellemembraner, og som kan forudsiges ved deres lipofile ("fedtelskende") egenskaber. En SAR model eller en QSAR model ((Quantitative) Structure Activity Relationship) er en relation mellem kemiske stoffers struktur og en givet aktivitet / egenskab. Den modellerede egenskab kan eksempelvis være en fysisk-kemisk egenskab eller en biologisk aktivitet, herunder en toksicitetsparameter. Ved udviklingen af en model sammenlignes en række kemiske stoffers struktur-egenskaber (molekylære deskriptorer) med målte værdier for den aktuelle egenskab for en gruppe stoffer kaldet et træningssæt. Målet er at fastlægge hvilke deskriptorer, der på en afgørende måde er forbundet med den undersøgte egenskab, og at sætte en relation op mellem disse deskriptorer og egenskaben. Deskriptorerne kan omfatte log Kow, molekylært index, kvantemekaniske egenskaber, form, størrelse, ladning, elektronfordelinger m.m. Sammenligningen udføres ofte ved brug af statistiske metoder. En SAR model kan give en kvalitativ forudsigelse af, om et stof besidder en given egenskab eller ikke, og en QSAR model kan give en kvantitativ forudsigelse af denne egenskab, eksempelvis en LD50-værdi. Det vil sige, at en QSAR model er en matematisk relation mellem kvantificerede deskriptorer for et kemisk stof og en mere eller mindre gradueret skala for den undersøgte egenskab. En sådan model kan bruges til ud fra deskriptorer for andre kemiske stoffer at give en kvantitativ forudsigelse for den modellerede egenskab. I dag anvendes sædvanligvis computere til udvikling og brug af QSAR modeller. 2.1.2 Modellernes domæneEn QSAR models domæne begrænser brugen af modellen til den egenskab, der er modelleret, og den gruppe af stoffer, som den kan give pålidelige forudsigelser for. Domænet defineres ved udvælgelsen af træningssættet. De områder af "det kemiske univers", som deskriptorerne i træningssættet "dækker" definerer området af kemiske stoffer, som modellen kan give gode forudsigelser for. 2.1.3 Nøjagtighed af modelforudsigelserModeller skal valideres for at fastslå, hvor gode deres forudsigelser er. En validering er en undersøgelse af en models forudsigelser for en gruppe stoffer, som er uafhængig af træningssættet, men som er inden for modellens domæne. Modellens forudsigelser for disse stoffer sammenlignes med målte værdier for den modellerede egenskab for at fastlægge nøjagtigheden / usikkerheden af modelforudsigelserne. Ideelt set skulle alle modeller valideres ved at blive afprøvet med en gruppe kemiske stoffer, der er uafhængigt af træningssættet. Dette er dog ikke altid simpelt. Dels fordi udelukkelsen af et sådant eksisterende datasæt fra selve modellens træningssæt kan betyde, at værdifuld information ikke bliver anvendt i modellen. Men også fordi det kan være uhyre vanskeligt at afgøre hvordan "eksterne" stoffer relaterer til modellens domæne – om de repræsenterer en vilkårlig udvælgelse der bredt dækker domænet, og dermed kan give et rimeligt billede af modellens præstationsevne. Disse problemer søges ofte løst ved at anvende én af flere mulige metoder for statistisk krydsvalidering. Det er en meget vigtig metode til at bestemme præstationsevnen for modeller, og i nogle tilfælde, når der kun kan findes få eller ingen testresultater for stoffer, der ikke blev brugt til at udvikle modellen, er denne metode den eneste tilgængelige. Den valideringsteknik, der oftest anvendes, er den såkaldte "drop one" eller "Q2" metode, hvor ét stof ad gangen fjernes fra træningssættet, og hvor en ny model udviklet på det reducerede træningssæt, bruges til at give en forudsigelse for stoffet. Dette gentages for alle stoffer i træningssættet. Skønt denne metode ofte anvendes, har den en tendens til at føre til en overvurdering af modellens kvalitet. En mere robust teknik til validering er eksempelvis metoden "3*10% ud", hvor 10% af stofferne i træningssættet fjernes, hvorefter en ny model udviklet på de resterende 90% bruges til at give forudsigelser for de udeladte stoffer. Denne procedure udføres sædvanligvis tre gange. Den kan også udføres indtil alle stoffer har været udeladt fra træningssættet, men tre gange vil generelt være tilstrækkeligt til at bestemme nøjagtigheden af korrelationen /50/. Resultatet af valideringen af en parametrisk model udtrykkes sædvanligvis som "sensitiviteten", "specificiteten" og "konkordansen" af modellen. Sensitiviteten er et mål for, hvor effektivt modellen "fanger" kemiske stoffer, som har den modellerede egenskab. En sensitivitet på 80% betyder, at modellen forudsiger 80% af de "ægte positive" i valideringssættet som positive, og at de resterende 20% ikke-korrekt forudsiges at være negative (falsk negative). Specificiteten er et mål for hvor mange falsk positive forudsigelser modellen giver. En specificitet på 80% betyder, at modellen forudsiger 80% af de "ægte negative" i valideringssættet som negative, og at de resterende 20% ikke-korrekt forudsiges at være positive (falsk positive). Konkordansen er et overordnet mål for korrektheden af forudsigelserne. En konkordans på 80% betyder, at modellen forudsiger 80% af stofferne i valideringssættet korrekt som positive eller negative, og at modellen giver ikke-korrekte forudsigelser for de resterende 20% (falsk negative og falsk positive). Modellens evne til at give korrekte forudsigelser afhænger både af den anvendte metode og den modellerede egenskab. Generelt kan gode QSAR modeller give korrekte forudsigelser for 70-85% af de kemiske stoffer den adspørges om, under forudsætning af at de er indenfor modellens domæne /53,54/. Dette gælder også de modeller, der blev anvendt i dette projekt. Naturligvis kan en model aldrig blive mere nøjagtig end de testdata, som den blev baseret på. Derfor er det uhyre vigtigt at være bevidst om nøjagtigheden og reproducerbarheden af de testdata, der anvendes til at lave en model. Hvis en biologisk test giver forkerte resultater i 17% af tilfældene, vil den "perfekte" model baseret på disse testdata også give forkerte forudsigelser i 17% af tilfældene. Udover at vurdere modellens evne til at give korrekte forudsigelser er det også nødvendigt at overveje i hvilken sammenhæng, modellen skal anvendes. I nogle tilfælde vil et stort antal "falsk positive" eller "falsk negative" være acceptabelt, mens det i andre tilfælde vil være uacceptabelt. I dette projet var der ingen bevidste forsøg på at justere modellernes vægt mod falske forudsigelser i nogen retning. Målet var opnå de mest korrekte forudsigelser for de undersøgte stoffer. Alternativet, når der ikke findes testdata eller andre relevante informationer om et stof, har ofte været at det ikke er blevet vurderet. 2.1.4 SoftwareI dag eksisterer der et stort antal computerprogrammer, som kan anvendes til at lave og bruge QSAR modeller for en lang række effekter fra bionedbrydelighed til kræft. Blandt disse er "fragment-baserede"* statistiske systemer som TOPKAT og M-CASE, såvel som systemer til tre-dimensionel modellering af "ligand docking"** såsom COMFA (Comparative Molecular Field Analysis). OASIS, en sofistikeret programpakke af systemer, der er i stand til at estimere en lang række effekter ved brug af 3D- og kvantemekaniske parametre, skal også nævnes i denne sammenhæng /46,47/. Systemet anvendes for øjeblikket blandt andet til estimering af kemiske stoffers bindingsaffiniteter til østrogen receptorer /48/. Den metode, som programmerne anvender i udviklingen og anvendelsen af QSAR modeller er i virkeligheden ikke ny. Programmerne grupperer ganske simpelt stoffer, der ligner hinanden mht. struktur og "globale" (for hele molekylet) eller "lokale" (for en del af molekylet) parametre såsom log Kow og elektrofilicitet på en måde, som eksperter stort set ville kunne gøre det. Men programmerne udfører det med meget høj hastighed, og de er i stand til at tage hensyn til et stort antal faktorer samtidig (såsom kritiske inter-atomiske afstande), og at gøre det fejlfrit. Dermed kan de hjælpe eksperter til at finde hidtil ikke erkendte sammenhænge. Derudover kan eksempelvis de nedenfor beskrevne programmer TOPKAT og M-CASE efterligne en anden menneskelig egenskab, nemlig at afvise at give estimater for et stof, hvor der simpelthen ikke er nok information i modellen til at give en pålidelig forudsigelse - dvs. at stoffet er udenfor modellens domæne. Programmerne udfører blot dette ved iterative statistiske metoder i stedet for ved menneskelig intelligens eller intuition. M-CASE M-CASE er et erfarings-baseret kunstigt intelligenssystem, der er i stand til at lære direkte fra data. Modeller sat op i dette program kan forudsige de modellerede toksiske egenskaber på basis af entydige fragmenter i stoffernes kemiske struktur. Disse fragmenter er i udviklingen af modellen fundet at være statistisk relevante for en specifik biologisk aktivitet, enten ved at forøge eller nedsætte denne aktivitet. Programmet kan dermed give en "kemisk" forklaring på observerede biologiske egenskaber. Antagelsen i programmet er, at tilstedeværelsen af fragmenter, som i træningssættet er overrepræsenterede i de aktive stoffer indikerer, at fragmentet potentielt er relateret til aktiviteten. Denne fragment-baserede metode antages at være en fornuftig basis til vurdering af aktiviteten af andre kemiske stoffer. På basis af tilstedeværelsen af fragmenter i den kemiske struktur for et stof vil programmet beregne en værdi for den egenskab, der er modelleret. Dette sker ved hjælp af "lokale QSARs" for de forskellige fragmenter, samt ved eventuelle "globale QSARs", hvis det er fundet, at der eksisterer en generel relation mellem en parameter og den modellerede egenskab, som det eksempelvis er tilfældet for log Kow og toksiciteten overfor akvatiske organismer. Programmet giver en advarsel, hvis der er fragmenter i det forespurgte stof, som ikke findes i træningssættet for modellen. Med advarslen indikerer programmet, at det forespurgte stof er udenfor modellens domæne /38,43/. Forudsigelser for stoffer, der er indenfor modellens domæne, og som modellen kan give pålidelige forudsigelser for, benævnes i denne rapport som AOKs ("All OK stoffer"). TOPKAT TOPKAT vurderer toksiciteten af kemiske stoffer ud fra deres kemiske struktur ved brug af QSTRs (Quantitative Structure Toxicity Relationships) modeller for specifikke skadelige sundhedseffekter /56/. Når en model i programmet forespørges ved at give modellen stoffets kemiske struktur, vil programmet først bestemme hvilken kemisk klasse stoffet tilhører. Dernæst vil programmet beregne de deskriptorer, der er nødvendige for beregningerne i en undermodel for denne kemiske klasse. Deskriptorerne kan for eksempel være elektro-topografisk tilstand, kappa index, molekylevægt, og symmetriindex. Programmet kontrollerer om alle de fragmenter, der er til stede i det forspurgte kemiske stof, var til stede med tilstrækkelig frekvens i træningssættet for modellen. Hvis der ikke er nogen fragmenter, der ikke er dækket tilstrækkeligt af modellen, checker programmet dernæst om forespørgslen er indenfor modellens domæne mht. den specifikke ligning. Hvis det er tilfældet gennemsøges den aktuelle lignings træningssæt for de stoffer, der mht. struktur ligner det forespurgte kemiske stof mest. Programmet kan bestemme overensstemmelsen mellem faktiske testdata og modellens forudsigelser for de stoffer, der kommer tættest på det forespurgte stof /45/. Hvis der er overensstemmelse for de fire mest statistisk relevante stoffer, accepteres modellens forudsigelse og benævnes i denne rapport som AOK analogt med forudsigelserne fra M-CASE. Epiwin Denne gruppe programmer udviklet af Syracuse Research Corporation blev i dette projekt anvendt til at beregne tre økotoksikologiske parametre: Bionedbrydning, log Kow og biokoncentration. I modsætning til TOPKAT og M-CASE, forsøger Epiwin ikke at vurdere om stofferne er inden for eller uden for modellernes domæne, og alle forudsigelser blev anvendt som givet af programmet. Chem-X I dette program er det muligt at estimere et stort antal forskellige fysisk-kemiske egenskaber, udvikle 2D og 3D-QSARs samt at lagre store mængder data og kemiske strukturer i databaser. Miljøstyrelsen har opbygget en database i Chem-X, som indeholder QSAR forudsigelser for omkring 166.000 kemiske stoffer /55/, dækkende næsten alle de organiske stoffer på Einecs med entydig kemisk struktur, i alt ca. 47.000 stoffer. Databasen indeholder forudsigelser for en række forskellige egenskaber, der dækker både sundheds- og miljø-effekter. Disse forudsigelser har dannet baggrund for de vejledende klassificeringer på den Vejledende liste til selvklassificering af farlige stoffer. Programmet giver detaljerede muligheder for at foretage søgninger, definere fremvisningen af data, samt at håndtere kemiske strukturer. Dette værktøj blev i stort omfang anvendt til at sammenligne testdata, forudsigelser og udvalgte understrukturer i ekspertvurderingerne af QSAR modellerne. Mulighederne for udbredelse af denne database med de specifikke QSAR forudsigelser er på nuværende tidspunkt uklare grundet spørgsmål om copyright. 2.2 Metodologien i udarbejdelsen af listen2.2.1 De udvalgte farlige egenskaberFølgende farlige egenskaber blev udvalgt til evaluering ved QSAR modeller:
2.2.2 De vurderede kemiske stofferDet overordnede formål med projektet var at vurdere så mange som muligt af de kemiske stoffer på Einecs (European Inventory of Existing Commercial Chemical Substances) /2/. Einecs består af 100.116 indgange indeholdende organiske eller uorganiske stoffer i enten enkeltstofindgange eller i indgange, der dækker grupper af stoffer. Evalueringen måtte af tekniske grunde begrænses til at dække organiske stoffer med en entydig kemisk struktur, da det ikke er praktisk muligt at lave/bruge modeller, når man ikke kender stoffets struktur. Det vil sige, at UVCB’er (Unknown, Variable Composition and Biologicals) og andre dårligt definerede strukturer eller blandinger måtte udelades. Undtagelser blev dog foretaget, hvor det blev vurderet rimeligt. Eksempelvis indgik C12-C16 n-alkoholer i vurderingen som C14 og hydrogenchlorid-salte indgik som modermolekylet osv. Uorganiske stoffer er ligeledes ikke blevet vurderet. Disse stoffer kan ofte vurderes ved simplere metoder for tilgængeligheden af de respektive an- og kationer med velkendte toksicitetsprofiler. "Organo-metaller" blev også udeladt fra vurderingen som dårlige kandidater for modellering. Endelig omfattede vurderingen, på grund af ressourcer, kun kemiske stoffer, hvor oplysninger om de tredimensionelle stukturer var tilgængelige /7/. Så vidt muligt blev alle stoffer, der allerede er klassificerede på den formelle liste i EU (Listen over farlige stoffer), ved brug af CAS nummer sammenligninger udeladt fra vurderingen, idet disse stoffer aldrig skal undergå selvklassificering. Dette resulterede i en "startliste" på 46.707 kemiske stoffer ud af Einecs fortegnelsens 100.116 stofindgange, som kunne undergå en systematisk vurdering ved hjælp af QSAR modeller. 2.2.3 TestresultaterFor langt størstedelen af de vurderede kemiske stoffer var eksperimentelle testresultater ikke tilgængelige i vurderingen. Men hvor de var tilgængelige som en del af de anvendte modeller, blev de generelt brugt fremfor modellernes forudsigelser. Det er vigtigt at understrege, at der ikke blev gjort nogen forsøg på at søge testresultater for stofferne i alverdens publicerede og ikke-publicerede datasamlinger over toksikologiske oplysninger, for at fastlægge om det var nødvendigt at foretage QSAR forudsigelser. Kortlægning af eksperimentelle testresultater er en opgave, som påhviler producenter / importører af de kemiske stoffer. 2.2.4 Brug af QSAR modellerDe tekniske specifikationer for de anvendte QSAR modeller og en beskrivelse af hvordan modellerne er blevet brugt til en systematisk vurdering af stofferne, er givet i de følgende fem kapitler for de udvalgte fem farlige egenskaber. Det skal betones, at de anvendte modeller ikke direkte giver forudsigelser af "klassificeringer", men at de giver forudsigelser om biologiske aktiviteter, som kan føre til en klassificering. Derfor blev der på basis af de formelle kriterier for klassificering og de tilgængelige modeller for de individuelle farlige egenskaber opsat "regler" for, hvordan modelforudsigelserne for biologisk aktivitet skulle anvendes til fastsættelse af vejledende klassificeringer. Anvendelsen af fastsatte "regler" gjorde det muligt at foretage en systematisk vurdering af det store antal stoffer på startlisten. Sådanne regler er ikke perfekte, men dybest set adskiller processen sig ikke fra den, der pålægges eksperter, når de skal selvklassificere et stof, hvor der ikke findes de ønskede testresultater. Kun de modelforudsigelser der opfyldte følgende kriterier blev anvendt: For M-CASE modeller skulle forudsigelserne være indenfor modellernes domæne, hvilket betyder, at der ikke må være fragmenter for det undersøgte stof, som modellen ikke kender. Modellen skulle være i stand til at give en pålidelig forudsigelse på baggrund af kendskab til alle stoffets fragmenter. Som beskrevet i kapitlerne for de individuelle farlige egenskaber er der så vidt muligt indenfor projektets rammer foretaget ekspert evaluering af sandsynligheden for, at QSAR modellernes forudsigelser var korrekte. Evalueringen omfattede undersøgelse af forudsigelsernes overensstemmelse med biologiske aktiviteter og kemiske egenskaber. Der er ikke blevet foretaget dybdegående toksikologiske vurderinger af de individuelle kemiske stoffer. Tvivlsomme forudsigelser indenfor en af de udvalgte farlige egenskaber medførte, at stoffet ikke blev tildelt vejledende klassificering for den pågældende farlige egenskab. Omfanget af ekspert evalueringerne varierede for de forskellige farlige egenskaber. Generelt blev den største indsats lagt på en vurdering af forudsigelserne for skader på arveanlæggene og kræftfremkaldende effekt, og den mindste indsats blev lagt på vurderinger af forudsigelser om allergifremkaldende virkning og farlighed for vandmiljøet. 2.2.5 ResultatetDet er vigtigt at understrege, at resultaterne af den systematiske vurdering som angivet på den Vejledende liste til selvklassificering af farlige stoffer, kun repræsenterer POSITIVE QSAR forudsigelser. Der er i udarbejdelsen af listen ikke skelnet mellem, om der for et stof var en negativ forudsigelse eller en upålidelig forudsigelse (en ikke-AOK forudsigelse), som blev udeladt. At et QSAR vurderet stof ikke er med på listen, eller at det er angivet på listen men uden vejledende klassificeringer for en eller flere af de udvalgte farlige egenskaber, kan altså enten skyldes, at modelforudsigelserne angav, at stoffet ikke havde den / disse farlige egenskaber, eller det kan skyldes, at modellerne ikke var i stand til at give en pålidelig forudsigelse for, om stoffet havde den / de farlige egenskaber. Listen kan derfor ikke bruges til at konkludere, at et specifikt stof ifølge QSAR modellerne ikke besidder de farlige egenskaber. Afhængigt af hvilken farlig egenskaber, der blev vurderet, var mellem 5% og 65% af forudsigelsene upålidelige. 2.3 Akut dødelig virkning ved indtagelseEU’s kriterie for klassificering Det formaliserede kriterie for klassificering for akut dødelig virkning ved indtagelse indeholder forskellige muligheder for tests, herunder test med den kritiske dosis (fastdosismetoden), og for tolkning af de forskellige kilder til oplysninger om akut dødelig virkning ved indtagelse. Klassificeringen baseres dog ofte på akutte LD50 testresultater i rotter, for hvilke følgende klassificeringskriterier anvendes: Tabel 3
Stoffer med forudsigelser eller testresultater, der viste at LD50 oral, rotte £ 2000 mg/kg, blev medtaget på listen med den vejledende klassificering Xn;R22. Der blev ikke gjort forsøg på at differentiere mellem de tre niveauer for farlighed, og det er vigtigt at bemærke, at den vejledende klassificering derfor ofte vil være mindre stringent end hvis klassificeringen var baseret direkte på testresultater. Hvis testresultater var lettilgængelige (havde været brugt til at udvikle modellen) blev disse anvendt frem for modelforudsigelser. Da testresultater for akut dødelig virkning ved indtagelse i nogle tilfælde var tilgængelige fra forsøg med mus, hvor stofferne var indtaget gennem andre veje end oralt, blev disse brugt til at forudsige rotte oral LD50 ved brug af følgende QSARs angivet efter præference /8,9/: Tabel 4
iv: Intravenøst (i vene) Testresultater for LD50 i enten mus eller rotter var tilgængelige for lige over 10% af de vurderede kemiske stoffer. For de stoffer uden sådanne testresultater blev rotte, oral LD50 beregnet ved en TOPKAT model (v. 5.01). Ifølge TOPKAT indeholder modellen ca. 4000 stoffer, og deres egen krydsvalidering af denne model viser, at 86-100% af modellens forudsigelser falder indenfor en faktor fem, når de sammenlignes med testresultater /10/. Miljøstyrelsens egen eksterne evaluering af modellen, hvor der blev brugt 1.840 kemiske stoffer, som ikke var del af modellens træningssæt, gav et noget ringere resultat; R2 = 0,31. Ifølge denne vurdering falder 86% af modellens forudsigelser indenfor en faktor ti, når de sammenlignes med testresultater /11/. Fordelingen kan ses i tabel 5. Tabel 5
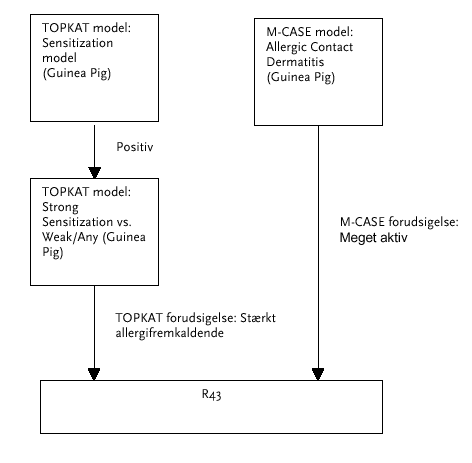
Ud af de stoffer, hvor TOPKAT modellen var i stand til at give en pålidelig forudsigelse (AOK), blev 57% af stofferne forudsagt at have en akut LD50 oral, rotte på £ 2000 mg/kg. Procentdelen af stoffer med en akut LD50 oral, rotte på £ 2000 mg/kg ud af 12.632 stoffer fundet i Registeret for toksiske effekter af kemiske stoffer, RTECS (RTECS 1998) /52/ var 61%. At procentdelen for TOPKATs forudsigelser og resultaterne i RTECS er så tæt på hinanden, er ikke overraskende, idet RTECS data var den primære kilde til testresultater til træningssættet for TOPKAT modellen. En skematisk oversigt over den systematiske vurdering er givet i figur 2. Figur 2 Ca. 10.200 stoffer havde ifølge beregningerne en akut LD50 oral, rotte på mindre end eller lig med 2.000 mg/kg***. Omkring 700 ud af disse blev ikke medtaget på den Vejledende liste til selvklassificering af farlige stoffer. Dette skyldtes, at en ekspertvurdering fandt, at det eksempelvis var aminosyre- og proteinstoffer, som sandsynligvis bliver nedbrudt af mavesyre før optagelse, eller at det var stoffer, hvor det forventes, at optagelsen vil være ringe. Dette resulterede i, at 9.538 stoffer blev medtaget på listen med den vejledende klassificering Xn;R22. 2.4 Allergifremkaldende effekt ved hudkontaktEU’s kriterie for klassificering Klassificering som allergifremkaldende ved hudkontakt, R43 ("Kan give overfølsomhed ved kontakt med huden"), er baseret enten på dyrestudier eller på praktisk erfaring, eller på en kombination af begge dele. Dyrekriteriet er baseret på test med eller uden hjælpestof. Der eksisterer flere forskellige metoder med hjælpestof til undersøgelse for hudsensibiliserende virkning, men Magnusson-Kligmann's metode (GPMT: Guinea Pig Maximization Test) er den foretrukne. For denne test resulterer respons i 30% af forsøgsdyrene i klassificering. For test uden hjælpestoffer (eksempelvis Büehler test) anses respons i 15% af forsøgsdyrene som et positivt resultat. Humane testresultater kan stamme fra lappetest, studier af enkeltepisoder eller epidemiologiske studier. Vurdering baseret på modelforudsigelser Der blev anvendt to fremgangsmåder til vurdering af hudsensibilisering /14,15/. I den første fremgangsmåde blev to TOPKAT QSTR modeller anvendt. Den første model blev anvendt til at forudsige om stoffet har allergifremkaldende effekt ved hudkontakt, og for de stoffer, hvor forudsigelserne var positive, blev den anden model anvendt til at forudsige "Stærk eller svag/moderat allergifremkaldende effekt". Modellerne er primært udviklet over testresultater fra Magnusson-Kligmann's metode (GPMT). Kun de stoffer, der ifølge modelforudsigelserne var stærkt allergifremkaldende, blev anset for med sandsynlighed at opfylde EU’s kriterie for klassificering med R43. I den anden fremgangsmåde blev en M-CASE model anvendt til forudsigelse af hudsensibiliserende virkning. Træningssættet, som er brugt til at udvikle M-CASE modellen, adskiller sig en del fra træningssættet til TOPKAT modellerne, da der i M-CASE modellen er anvendt testresultater fra både GPMT og humane resultater. For M-CASE modellen blev kun positive forudsigelser af allergifremkaldende effekt med en M-CASE score på > 40 (svarende til "meget aktiv") anset for med sandsynlighed at opfylde EU’s kriterie for klassificering med R43. Tabel 6
Det er vanskeligt at afgøre hvor repræsentative de nye kemiske stoffer er for "kemikalieuniverset". Generelt har nye kemiske stoffer mere komplekse strukturer og højere molekylvægt. Den måske mest overraskende side af denne valideringsøvelse var opdagelsen af, at der ud af mere end tre tusinde nye anmeldte kemiske stoffer kun var en lille procentdel af stofferne, der havde brugbare testresultater for allergifremkaldende effekt ved hudkontakt. Kun stoffer, der havde AOK forudsigelser i de anvendte modeller, blev taget i betragtning i den regelbaserede vurdering. Det blev overvejet at anvende et kriterium om, at stofferne skulle have positive forudsigelser fra både TOPKAT og M-CASE modeller for at forøge sikkerheden i vurderingen, men dette viste sig ikke at virke efter hensigten. Ikke fordi der ikke var overensstemmelse mellem modelforudsigelserne, men fordi modellernes domæner var væsentligt forskellige, og der derfor var et stort antal stoffer, der kun havde en AOK forudsigelse i en af modellerne. Der blev ikke gjort nogen forsøg på systematisk at ekspertvurdere forudsigelserne af allergifremkaldende effekt ved hudkontakt. En skematisk oversigt over den systematiske vurdering er givet i figur 3.
Figur 3 9.668 kemiske stoffer blev i den systematiske vurdering efter de beskrevne kriterier fundet at have allergifremkaldende effekt ved hudkontakt, og de blev medtaget på den Vejledende liste til selvklassificering af farlige stoffer med R43. Dette antal kan virke temmelig stort for mange eksperter, og selv om de anvendte modeller repræsenterer "state-of-the-art", kan det være udtryk for, at de er meget følsomme. Det er dog meget svært at finde nogen pålidelige indikationer af, hvor mange af de eksisterende kemiske stoffer, der ville være hudsensibiliserende, hvis de blev testede på dyr eller mennesker. Forskellige vurderinger af hvor stor en procentdel af stofferne på Einecs, der er allergener, har strakt sig fra 5-25% med en vis præference for en procentdel på 10%. Ser man på Annex I stoffer (Listen over farlige stoffer) er der i dag ca. 10% af stofferne, der er klassificerede med R43. Det er dog ikke muligt at vurdere, om denne procentdel er repræsentativ for alle de eksisterende stoffer. Positiv bias kan være tilstede, fordi kemiske stoffer, der ved test er fundet at være positive, er overrepræsenterede. Negativ bias kan være forårsaget af, at de fleste af stofferne på Annex I aldrig er blevet testet for denne effekt. Spørgsmålet står åbent. 2.5 Skader på arveanlæggeneEU’s kriterie for klassificering Indenfor denne farlige egenskab er klassificeringen opdelt i tre kategorier: Klassificering som mutagen, kategori 1 (mut1;R46, Kan forårsage arvelige genetiske skader) er baseret på bevis på en årsagssammenhæng mellem udsættelse for stoffet og forekomst af arvelige skader på det genetiske materiale hos mennesker. Klassificering som mutagen, kategori 2 (mut2; R46, Kan forårsage arvelige genetiske skader) er baseret på dyreforsøg, der viser mutagenicitet i kønsceller enten fra forsøg på kønsceller eller fra forsøg, hvor der er demonstreret mutagene effekter i somatiske celler in vivo eller in vitro såvel som etableret bevis for, at stoffet vil nå kønscellerne. Klassificering som mutagen, kategori 3 (mut3;R40, Mulighed for varig skade på helbred) er baseret på enten in vivo mutagenicitetstest eller testresultater for cellulære påvirkninger med in vitro forsøg som understøttende bevis. For denne klassificering er det ikke nødvendigt at demonstrere kønscellemutationer. Vurdering baseret på modelforudsigelser Der blev anvendt en række modeller til vurdering af mutagenicitet. De forskellige modeller dækker et antal forskellige genotoksiske effekter. Forudsigelse af induktion af mikronuclei i in vivo forsøg blev anvendt i den systematiske vurdering til at demonstrere kromosomskader i somatiske celler in vivo. De resterende anvendte modeller giver forudsigelser for genotoksicitet in vitro. Positive testresultater i in vitro forsøg for genotoksicitet ville sædvanligvis føre til en klassificering for mutagenicitet, kategori 3. I den systematiske vurdering blev modelforudsigelserne for in vitro genotoksicitet anvendt som understøttende bevis for in vivo forudsigelserne af induktion af mikronuclei. Tabel 7
Dette skal ikke ses som et udtryk for, at det foreslås, at positive in vivo testresultater skal understøttes af in vitro testresultater i klassificeringskriterierne. Men det er et udtryk for, at det blev vurderet, at de vejledende klassificeringer skulle baseres på mere end modelforudsigelser om induktion af mikronuclei alene. Disse blev derfor understøttet af forudsigelser fra andre relevante QSAR modeller for at forøge sandsynligheden for, at de positive forudsigelser var korrekte. Kriteriet for mutagenicitet i den systematiske vurdering var, at det vurderede stof skulle have positive modelforudsigelser for strukturelle indikationer på DNA reaktivitet**** (Structural Alert) og induktion af mikronuclei, og mindst to positive forudsigelser for de resterende genotoksiske effekter. Der blev anvendt to modeller for Salmonella (Ames test) mutagenicitet, henholdsvis en TOPKAT og en M-CASE model. Dette skyldes, at de to modeller adskilte sig med hensyn til deres domæner, og at der for mange stoffer kun var pålidelige forudsigelser fra den ene model. Hvis pålidelige modelforudsigelser var tilgængelige fra begge modeller, men de var i modstrid med hinanden, blev det vurderet i hvert tilfælde i den sidste evaluering af stofferne. En skematisk oversigt over den systematiske vurdering er givet i figur 4. Figur 4 2.272 stoffer opfyldte kriterierne for den systematiske vurdering. Da ingen af de anvendte modeller identificerede mutagenicitet i kønsceller, kunne de dermed ikke anvendes til en diskrimination mellem EU’s formelle klassificeringskriterier for mutagenicitet i de tre kategorier. Den laveste klassificering, mutagen kategori 3, blev derfor givet som vejledende klassificering for de stoffer, der i denne vurdering blev fundet at være mutagene. Der blev foretaget ekspertvurderinger af pålideligheden af forudsigelserne for de 2.272 stoffer, der opfyldte de opsatte kriterier for klassificering for mutagenicitet. Denne proces omfattede undersøgelse af den to- eller tre-dimensionelle struktur, og visuel sammenligning med testresultater indenfor grupper af strukturelt lignende stoffer. Hvis der i denne undersøgelse blev rejst nogen tvivl om pålideligheden, blev stoffet ført over på en liste over stoffer, der skal undersøges nærmere. Dette førte til en endelig udvælgelse af 1.678 stoffer med den vejledende klassificering mut3;R40. 2.6 Kræftfremkaldende effektEU’s kriterie for klassificering Indenfor denne farlige egenskab er klassificeringen opdelt i tre kategorier: Klassificering som kræftfremkaldende kategori 1 (carc1;R45, Giftig; kan fremkalde kræft eller carc1;R49, Giftig; kan fremkalde kræft ved indånding) er baseret på beviser for en stærk årsagssammenhæng mellem udsættelse for stoffet og udvikling af kræft hos mennesker. Klassificering som kræftfremkaldende kategori 2 (carc2;R45, Giftig; kan fremkalde kræft eller carc2;R49, Giftig; kan fremkalde kræft ved indånding) er baseret på baggrund af egnede langtidsforsøg i dyr for mindst to dyrearter eller for én art med understøttende beviser, såsom genotoksiske effekter in vitro eller in vivo. Klassificering som kræftfremkaldende kategori 3 (carc3;R40, Sundhedsskadelig; mulighed for varig skade for helbred) er opdelt i:
Vurdering baseret på modelforudsigelser Mange ikke-genotoksiske kræftfremkaldende stoffer virker gennem en række ofte ukendte mekanismer. Der blev i dette projekt fokuseret på de kemiske stoffer, som mistænkes for at fremkalde kræft gennem genotoksiske mekanismer. Der blev derfor sat et genotoksisk udvælgelseskriterie op. Kun de stoffer, der havde en positiv forudsigelse for strukturelle indikationer på DNA reaktivitet (AOK forudsigelser eller ét ukendt fragment) samt to positive forudsigelser fra fem modeller for genotoksicitet, blev udvalgt til at blive vurderet ved hjælp af kræftmodellerne. De tekniske specifikationer for de anvendte genotoksicitets-modeller er givet i kapitlet om skader på arveanlæggene. I modsætning til kriterierne for skader på arveanlæggene var der i det genotoksiske kriterie ikke krav om en positiv forudsigelse for dannelse af mikronuclei i mus, idet genotoksiske kræftfremkaldende stoffer ikke nødvendigvis er klastogene (forårsager tab, addition eller ændring af dele af kromosomer). Der var 3.362 Einecs stoffer, der opfyldte det genotoksiske udvælgelseskriterie. Der blev anvendt ti modeller og fire undermodeller for kræftfremkaldende effekt. Tabel 8
* NTP: National Toxicology Program, USA Nøjagtigheden af forudsigelserne fra disse modeller kan være svær at bestemme ved eksterne valideringer, idet der kun findes meget få uafhængige testresultater, som ikke allerede er anvendt i modellernes træningssæt. Dette gælder især TOPKAT modellerne, hvor de eneste bestemmelser af nøjagtigheden fra producenten er baserede på valideringer ved "Q2" metoden ("one out"). For M-CASE modellerne er der blevet anvendt andre statistiske metoder til bestemmelse af nøjagtigheden. I et længerevarende projekt, hvor adskillige modeller for kræftfremkaldende effekt gav forudsigelser for 45 kemiske stoffer, som endnu ikke var blevet testede i USA’s NTP-program, var den generelle konklusion ved efterfølgende test af stofferne, at nøjagtigheden af modellerne var omkring 70% for de stoffer, der klart kunne siges at være enten kræftfremkaldende eller ikke-kræftfremkaldende /31/. På grund af det begrænsede antal stoffer i denne eksterne validering er det svært at vurdere hvor meget vægt, der kan lægges på denne konklusion. De 3.362 stoffer, der passerede det genotoksiske udvælgelseskriterie, og derfor efterfølgende blev vurderet for kræftfremkaldende effekt, skulle opfylde følgende kriterie for udvælgelse: Der skulle mindst være positive forudsigelser fra to af modellerne (undermodellerne ikke medregnet). En undtagelse blev gjort for de to M-CASE CPDB modeller. Da træningssættene for disse modeller er mindre homogene skulle begge modeller give en positiv forudsigelse for at kunne gælde som én positiv forudsigelse. Derudover var kravet til den estimerede styrke af den kræftfremkaldende effekt, at TD50 skulle være mindre end 1.000 mg/kg/dag. Disse to modeller blev udviklet af Miljøstyrelsen ved brug af M-CASE metodologien, som er beskrevet for de her anvendte datasæt i referencerne /34,35,40/. Hvis testresultater for kræftfremkaldende effekt var tilgængelige for de vurderede kemiske stoffer (indgik i modellernes træningssæt), blev disse anvendt fremfor modelforudsigelserne og resulterede i en direkte udvælgelse af stofferne til den Vejledende liste for denne farlige egenskab. Selvom dette i de fleste tilfælde ikke ændrede på hvilke stoffer, der blev udvalgt til listen (fordi modellerne har en stor tilbøjelighed til at give korrekte forudsigelser for de stoffer der indgår i træningssættet), blev det vurderet at være mere korrekt at basere de vejledende klassificeringer på modelforudsigelser, når der var testresultater til stede. En skematisk oversigt over den systematiske vurdering er givet i figur 5. Figur 5 Ifølge disse kriterier blev 1.272 efter den systematiske vurdering fundet at skulle klassificers for kræftfremkaldende effekt. Der blev udført ekspertvurderinger på QSAR-modellerne. I denne proces blev alle data gennemgået, herunder også forudsigelser fra de fire TOPKAT FDA modeller, sandsynligheder for hurtig metabolisme eller udskillelse blev vurderet, og hvor det var passende vurderinger af aryl hydroxylase aktiviteter /37/. Hvor der på denne måde blev rest tvivl om forudsigelsen af kræftfremkaldende effekt, blev stofferne ført over på en liste over stoffer, der skal undersøges nærmere, og de blev ikke inkluderede i denne første udgave af den Vejledende liste til selvklassificering af farlige stoffer. Dette resulterede i, at 652 stoffer blev medtaget på listen med vejledende klassificeringer for kræftfremkaldende effekt. Da det blev vurderet, at de anvendte modeller ikke kunne danne grundlag for en skelnen mellem klassificering i de tre kategorier, blev den laveste klassificering Carc3;R40 anbefalet i alle tilfælde. 2.7 Farlighed for vandmiljøetEU’s kriterie for klassificering Klassificeringskriteriet er sammensat af tre hovedelementer: Bionedbrydning, biokoncentreringspotentiale og giftig virkning overfor akvatiske organismer. Klassificeringer baseret på farlighed for akvatiske organismer gives i overensstemmelse med kriterierne i nedenstående tabel. Tabel 9
* Den laveste effektkoncentration for fisk, dafnier eller alger anvendes Vurdering baseret på modelforudsigelser Vejledende klassificeringer blev givet til stoffer, der på basis af computerforudsigelser for bionedbrydning, biokoncentrering og akut giftighed for fisk opfyldte kriterierne for klassificering angivet i tabel 9. Der blev på baggrund af den systematiske vurdering ikke givet vejledende klassificeringer med R53 alene, da den stærke sammenhæng mellem vandopløselighed og biokoncentreringsfaktoren gjorde denne klassificering overflødig. Bionedbrydning Bionedbrydning blev estimeret ved brug af Syracuse’s BIOWIN program (v. 3.02) /17,41/. Der blev kun anvendt den lineære ligning for hurtig / ikke-hurtig bionedbrydning. Tidligere validering af denne QSAR ved brug af såkaldte "ready / not-ready" testresultater fra MITI-programmet viste, at mens der var en del "not-ready" (ikke let-nedbrydelige) stoffer, der ikke blev fanget, var der ud af modellens forudsigelser af "not-ready" 93% som var korrekte /18/. Med andre ord vil denne model ikke fange alle de ikke let-nedbrydelige stoffer, men antallet af falsk positive forudsigelser for mangel på nedbrydelighed er acceptabelt lille. Et totalantal på ca. 14.000 Einecs stoffer blev med denne model fundet at være "ikke-letnedbrydelige" ifølge kriteriet /51/*****. Biokoncentrering I EU’s klassificeringskriterie foretrækkes målte testresultater for biokoncentrering i fisk, men da disse sjældent er tilstede eller er af mindre god kvalitet anvendes i stedet, når dette er tilfældet, log Kow større end eller lig med 3,0 som indikation for, at BCF vil være 100 eller derover. Dette er i overensstemmelse med den lineære ligning fra Vieth og Kosian /41/. Selvom dette er en god tommelfingerregel, vil den føre til både over- og underestimeringer af BCF for mange klasser af stoffer. Derudover tager den ikke højde for det faktum, at biokoncentrering er en bilineær funktion af log Kow, der aftager når log Kow er tilstrækkeligt høj. Syracuse’s BCFWIN (v. 2.13) blev af denne grund anvendt til at give forudsigelser for biokoncentrationsfaktoren i fisk. Denne metode er baseret på en kombination af log Kow QSARs og strukturelle fragmentkategorier. Ifølge en evaluering udført af skaberne af metoden er resultatet af den statistiske evaluering at R2 = 0,74 (n = 694, S.D. = 0,65, S.E. = 0,47), hvilket er en signifikant forbedring i forhold til standardligningen fra Vieth og Kosian (log BCF = 0,85 * log Kow – 0,70), hvor forudsigelserne for de samme 694 stoffer havde en statistisk nøjagtighed på R2 = 0,32 (S.D. = 1,62, S.E. = 1,12) /20/. Omkring 11.000 af de vurderede Einecs stoffer har ifølge den anvendte model BCF værdier på 100 eller derover. Der blev ikke gjort nogen forsøg på yderligere at fastlægge bioakkumuleringspotentialet dækkende den del, der henhører til optagelsen fra føden, på grund af manglende egnede modeller til forudsigelse af denne effekt. Akut giftighed I klassificeringen for farlighed for vandmiljøet anbefales det at anvende værdier for akut giftighed (L(E)C50) overfor både fisk, dafnier og alger, selvom det generelt er sjældent, at der for Einecs stoffer er værdier for alle tre arter. I denne systematiske vurdering med QSAR modeller blev det besluttet kun at anvende forudsigelser for giftigheden for fisk, på grund af deres pålidelighed og tilgængeligheden af testresultater af høj kvalitet til modeludvikling. Til at beregne den akutte giftighed overfor fisk udviklede Miljøstyrelsen en M-CASE model. Der blev anvendt et træningssæt med 569 96-timers LC50 testresultater fra Duluth Fathead minnow databasen /22/. Intern verifikation af modellen gav R2 = 0,85. Krydsvalidering ved "3*10% ud" metoden gav R2 = 0,735. En beskrivelse af M-CASE metodologien anvendt på Fathead minnow testresultater er givet i referencerne /21,42/. Kun AOK forudsigelser blev anvendt i den systematiske vurdering. Da der ikke var tilstrækkelig mange meget lipofile stoffer i træningssættet til modellen, blev den kun anvendt til vurdering af stoffer med log Kow på 6 eller derunder. For stoffer med log Kow over 6 blev der anvendt en anden QSAR. For disse stoffer blev det antaget, at de virkede ved ikke-polær narkotisk virkning og toksiciteten ved ligevægt blev beregnet ved følgende ligning udfra den beregnede biokoncentrerings-faktor: LC50 (ligevægt) = 8,15 mmol / BCF Anvendelsen af denne ligning er i overensstemmelse med det teoretiske niveau til inducering af akvatiske effekter, angivet ved QSAR’en for ikke-polær narkotisk virkning på fisk, som er anbefalet i EU’s Technical Guidance Document (til risikovurdering af kemiske stoffer) /41/. Dødelige koncentrationer (LBB: Lethal Body Burden) i fisk udfra ikke-polær narkotisk virkning antages generelt omtrent at ligge i intervallet 2-8 mmol/kg /23,58/. Selvom simple log Kow QSARs eksisterer til forudsigelse af ikke-polær narkotisk virkning for fisk, dafnier og alger /41/, er disse ikke i stand til at forudsige, om der er specifik toksicitet, der er unik indenfor hver af de tre arter. Det er derfor ikke en fordel at anvende disse QSARs frem for at anvende fiske-modellen alene, da denne også giver fyldestgørende forudsigelser af ikke-polær narkotiske virkning såvel for fisk som for dafnier og alger, idet det er en rimelig antagelse, at ikke-polær narkotisk virkning giver effekt ved det samme koncentrationsniveau for alle tre arter /18/. Ved brug af M-CASE modellen og den angivne QSAR blev omtrent 10.000 Einecs stoffer udfra den systematiske vurdering fundet at være akut giftige for fisk med LC50 £ 100 mg/l. Figur 6 I alt 8.731 stoffer blev efter den systematiske vurdering angivet på den Vejledende liste til selvklassificeringer af farlige stoffer med vejledende klassificeringer for en af de fire udvalgte klassificerings-kategorier for farlighed for vandmiljøet. Taget i betragtning at der var AOK forudsigelser for giftigheden overfor fisk for lidt under halvdelen af antallet af de vurderede kemiske stoffer, synes antallet af stoffer, der er farlige for vandmiljøet, at være i overensstemmelse med hvad der kan forventes for Einecs stoffer. Fordelen ved at kunne forudsige giftige effekter, som er specifikke for både fisk, dafnier og alger er åbenlyse, og dette kan forhåbentlig opnås i fremtiden. Miljøstyrelsen har for nylig udviklet en M-CASE model for akut giftighed overfor dafnier (n = 574, R2 = 8,826, ved "3*10% ud" metoden er R2 = 0,692). Denne model undergår stadig videreudvikling. En M-CASE model for akut giftighed overfor alger er ligeledes under udvikling. I fragment-baserede programmer baseres forudsigelsen på forekomsten af molekylære understrukturer. I en model for "ligand docking" ønskes en forudsigelse af, hvor godt et kemiske stof passer ind i en bestemt rumlig struktur af et makromolekyle med biologisk betydning, såsom en receptor (f.eks. en hormonreceptor). TOPKAT beregninger blev også udført for rotters kroniske LOAEL (lavest observerede skadelige effekt-niveau). Nøjagtigheden bestemt ved krydsvalidering var i samme størrelsesorden som for den anvendte model for akut giftighed, med 95% af forudsigelserne indenfor en faktor 3-5 af de målte værdier /13,44/. Der er dog ingen EU klassificeringer, der er relaterede specifikt til denne farlige egenskab (men snarere til "alvorlig effekter på morfologi eller gifteffekter efter gentagen dosering", R48). Der blev derfor ikke foreslået nogen klassificering for denne farlige egenskab. Forudsigelser fra M-CASE modellen for DNA reaktivitet blev accepterede selvom de havde "ét ukendt fragment". Miljøstyrelsen har efter projektet med den Vejledende liste til selvklassificering af farlige stoffer udviklet en M-CASE model for bionedbrydning baseret på nye MITI data, som ifølge de første evalueringer synes at give betydeligt bedre forudsigelser. Resultatet af en validering ved "3*10% ud" metoden gav 81% korrekte forudsigelser af "not-ready" og 76% for "ready". En ekstern validering med brug af 72 "not ready" stoffer, som ikke var i modellens træningssæt gav 89% korrekte forudsigelser. Yderligere analyse og finjustering af denne model er under udarbejdelse /19/.
|