|
Kortlćgning af diffus jordforurening i byomrĺder. Delrapport 3 Bilag
A
|
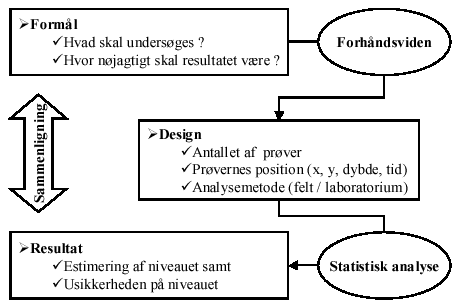
Element i Figur 1 |
Uddybende forklaring |
Formĺl |
At beskrive niveauet af ét eller flere stoffer indenfor et afgrćnset omrĺde (ogsĺ at vurdere niveauet hvor der ikke er udtaget prřver). Endvidere břr nćvnes hvilke konsekvenser forskellige resultater vil fĺ. |
Hvad skal undersřges ? |
Koncentrationen af stof X, f.eks. angivet (mg X/g TS). |
Hvor nřjagtigt skal resultatet vćre |
Det skal kunne vurderes om stof X overstiger en given grćnsevćrdi. Der řnskes derfor et konfidensinterval omkring de estimerede vćrdier. Usikkerheden pĺ estimatet er faktisk mere interessant end estimatet ! |
Forhĺndsviden |
Er der tidligere lavet undersřgelser i samme omrĺde inddrages informationer fra disse. Historiske oplysninger om arealanvendelse kan give oplysninger om forureningskilder. Undersřgelser fra lignende omrĺder kan give indtryk af variationen i niveauet. Hvad er baggrundsniveauet og variation i ikke-forurenet jord ? |
Design |
Beskriver undersřgelsesomrĺdet, antallet af prřver der skal undersřges, hvornĺr de skal foretages samt hvordan de skal analyseres. |
Antallet af |
Hvor mange prřver skal der undersřges. |
Prřvernes position (x, y, dybde, tid) |
Prřvernes position indenfor det geografiske omrĺde samt dybden hvorfra de skal udtages. Endvidere břr prřvetagningstidspunkt for de enkelte prřver fremgĺ. Et formĺl kunne vćre at fřlge udvikling over tid. |
Analysemetode (felt / laboratorium) |
Skal prřverne analyseres med flere metoder ? |
Statistisk analyse |
Der er to dele i en statistisk analyse, en beskrivelse af data og en statistisk model af niveauet baseret pĺ data. Den beskrivende del indeholder generelle deskriptive střrrelser, samt en beskrivelse af den geografiske variation. Kvantitativ og visuel inspektion. Model beskrivelsen udnytter den geografiske variation i data til at estimere niveauet samt usikkerheden pĺ dette i hele omrĺdet. Dette kan gřres pĺ forskellige mĺder. Modellerne anvender vćgtede interpolations-metoder baseret pĺ mĺlinger i nćrheden. Mĺden de omkringliggende observationer udnyttes pĺ er, alt andet lige, afgřrende for resultatet. Det bemćrkes at "alle modeller er forkerte men nogle er brugbare" |
Resultat |
Angives ofte som et interpoleret kontur-kort |
Estimat af niveauet |
Angivelse af koncentrationen af stof X i hele omrĺdet. |
Usikkerheden pĺ niveauet |
Usikkerheden pĺ angivelsen, oftest som en standard afvigelse eller et konfidensinterval |
2.1 Forureningskilder
Diffus jordforurening kan stamme fra en eller flere kilder. Det er ikke muligt at prćsentere et generelt design til undersřgelse af diffus jordforurening idet kilderne til diffus jordforurening kan variere mellem omrĺder samt indenfor omrĺder. I Figur 2 er angivet eksempler pĺ udbredelsen af forskellige former for diffus jordforurening Disse kunne stamme fra forskellige kilder
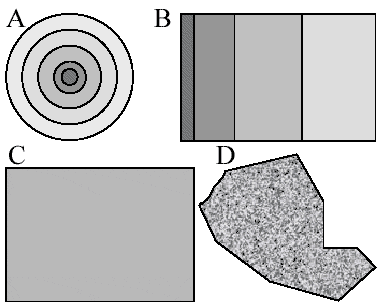
Figur 2
Forskellige forureningstyper, mřrk farve indikerer hřj koncentration og lys lav
koncentration. A: Punktkilde, B: Linjekilde, C: Overfladekilder, D: Mange smĺ tilfćldige
kilder.
Different pollutant types: Dark and light colours indicate high and low concentrations
respectively. A. Point sources. B. Line sources. C. Uniform surface sources. D. Many small
haphazard sources.
Beskrivelsen i Figur 2 er ikke udtřmmende og variationerne er uendelige. Variationer over A kunne vćre en ellipse, eller et cirkel udsnit forĺrsaget af vind eller andre pĺvirkninger. Variationer over B kunne vćre en krum linje hvor deponering/niveauer ikke fordeltes jćvnt med afstanden, indflydelse af bygninger mv. Variationer over C kunne vćre parceller hvor forureningen er ens indenfor parceller og forskellig mellem parceller. Variationer over D kunne vćre lokale omrĺder der er mere homogene end andre eller lokale omrĺder med varierende koncentrationer grundet forskellig oprindelse.
Der vil i sagens natur skulle anvendes forskelligt stikprřveplaner for at kunne beskrive variationen i de scenarier beskrevet i Figur 2. Det er derfor vigtigt (ikke overraskende) at forhĺndsviden om omrĺdet inddrages i planlćgning af undersřgelsen. Med den historiske arealanvendelse, resultater fra eventuelle tidligere undersřgelse, meteologiske forhold samt řvrige relevante oplysninger břr der kunne dannes en forestilling om, hvordan forureningen varierer indenfor omrĺdet.
Denne forestilling břr formuleres som en hypotese:
| Eksempel I) Det antages at blyindholdet i jorden aftager med afstanden fra vejen, den sydlige ende af arealet vurderes mindre belastet grundet afskćrmning mod vejen. |
| Eksempel II) Jorden antages at vćre opblandet i en sĺdan grad at der ikke er nogen struktur i koncentrationsniveauet. Der vurderes at vćre en tilfćldig fordeling af koncentrationsniveauet i omrĺdet. Dog antages det, baseret pĺ tidligere undersřgelser, at niveauet er under grćnsevćrdien. |
Hypoteserne beskrevet i eksempel I og II břr lede til to forskellige forsřgsplaner. Fra I) břr der kunne vurderes om trenden er som beskrevet og fra II) skal der undersřges om der findes koncentrationer over grćnsevćrdien. I det efterfřlgende uddybes betydningen af forsřgsdesignets indflydelse pĺ vurderingen af den spatielle variation.
2.2 Indflydelse af forsřgsdesign pĺ koncentrationsbestemmelse og usikkerhed
Som det vil fremgĺ af beskrivelsen af de statistiske vćrktřjer, der anvendes til at beskrive de data der fremkommer fra analyserne, er der en rćkke egenskaber ved forsřgsdesignet der har betydning for estimationen af niveauet og usikkerheden pĺ dette.
Det optimale design i forhold til estimationen er desvćrre ikke optimalt i forhold til usikkerheden pĺ denne. I Figur 3 er skitseret en hypotetisk diffus jordforurening. Grĺtoningen beskriver niveauet af det undersřgte stof (mřrk=hřj, lys=lav). Der er en diagonal trend fra řverste venstre hjřrne mod nederste hřjre hjřrne. De hvide cirkler angiver punkter, hvor der udtages prřver.
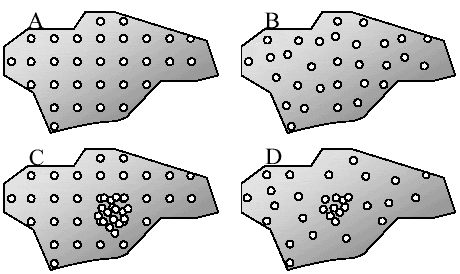
Figur 3
Forskellige undersřgelsesplaner.
Different investigation strategies
I A, C, D er udtaget prřver fra 30 positioner, hvor der i C er udtaget prřver fra 48 positioner. I A er et fastnet med ens afstand l mellem alle positioner, i B er positionerne tilfćldige, i C et fast net med ens afstand l mellem alle positioner tilfřjet 18 tilfćldige positioner indenfor et begrćnset omrĺde og i D er positionerne tilfćldige dog er 10 positioner indenfor et begrćnset omrĺde.
I det fřlgende vil blive beskrevet hvilken indflydelse de forskellige designs A-D har pĺ den videre analyse af data. Alle spatielle analyser udnytter at mĺlinger fra positioner tćt pĺ hinanden er mere ens end mĺlinger fra positioner langt pĺ hinanden. Udtages der prřver "lige ved siden af hinanden" forventes det at prřver har stor lighed (er korrelerede). Prřver udtaget i hver sin ende af omrĺdet forventes derimod ikke nřdvendigvis at vćre ens. Afstanden mellem observationerne er omdrejningspunktet i det fřlgende
Variansen af mĺlingerne kan anvendes som et mĺl for "ensheden" (en lille varians mellem observationer/mĺlinger betyder de er meget ens/korrelerede og en stor varians mellem observationer/mĺlinger betyder de er meget forskellige ens/ikke-korrelerede). Fřrste trin i en vurdering af variansens afhćngighed af afstanden mellem mĺlepositionerne er at dele den maksimale afstand mellem to mĺlinger i eksempelvis 10 intervaller (maksimal afstand 1000m; der inddeles i intervaller af 100m). Andet trin er at finde alle kombinationer af to mĺlepunkter der har en indbyrdes afstand indenfor hvert af de pĺgćldende intervaller (30 par i intervallet fra 0-100m, 47 par i intervallet fra 100-200m, …, 12 par i intervallet fra 900-1000m ). Tredje trin er at beregne variansen af punkterne i hvert af intervallerne. (variansen af de 30 par i intervallet 0-100m, variansen af de 47 par i intervallet 100-200m, …, variansen af de 12 par i intervallet fra 900-1000m). Herved kan man vurdere om variansen vokser med afstanden mellem observationerne. En vćsentlig ting at bemćrke er at vurdering af variansen indenfor afstande mindre end afstanden mellem de to nćrmeste punkter er gćtteri. Der fastlćgges altsĺ et minimumsvariationsniveau ud fra de nćrmeste punkter i analysen. Med andre ord er vurdering af variationer pĺ en skala mindre end denne afstand ekstrapolation. Derfor er den generelle opfattelse, blandt geostatistikere, at det er vigtigt at have nogle mĺlinger meget tćt pĺ hinanden samt gerne gentagne mĺlinger pĺ samme position (evt samme prřve). Se endvidere afsnittet pĺ geografisk korrelation.
Betragtes figur 3 eksempel A vil det ikke vćre muligt at vurdere den spatielle variation pĺ en skala mindre end maskestřrrelsen i "nettet". I figur 3 eksempel B er det muligt at vurdere den spatielle variation fra en skala svarende ca. til den mindste afstand af de tilfćldige placerede mĺlinger. I figur 3 eksempel C og D opnĺs der derimod information om variationen pĺ langt mindre skala (afstand). Denne information er vigtig for at kunne minimere usikkerheden pĺ estimationen.
Relateres Figur 2 og Figur 3 kan fřlgende opsummeres. Det anvendte forsřgsdesign skal afspejle den hypotese der er beskrevet for omrĺdet. Forventes en forureningsfane skal der foretages mĺlinger i fanen sĺ dens udbredelse kan fřlges. Omvendt forventes forureningen at vćre af mere tilfćldig karakter, er der ikke grund til at prřverne skal udtages pĺ bestemt positioner. Variationen mellem de nćrmeste punkter bliver et minimumsvariansniveau og en minimumsinterpolationsafstand. Disse betragtningerne om variation uddybes i afsnittet om geografisk korrelation.
3. Analyse
3.1 Deskriptiv statistik
Som i enhver anden statistisk analyse břr der indledes med en rćkke deskriptive mĺl og som minimum: Antal data, Fraktiler (minimum, median og maksimum), middelvćrdi og spredning, histogrammer samt fordelingsplot. Se et eksempel i bilag B.
Hvis de enkelte jordprřver er analyseret for flere forskellige stoffer břr korrelationen mellem enkeltstofferne beregnes. En hřj korrelationskoefficient (tćt pĺ 1 henholdsvis -1) betyder at to stoffer er positivt henholdsvis negativt korrelerede. En lav korrelationskoefficient (numerisk tćt pĺ 0) betyder at der ikke er sammenhćng mellem de to enkeltstoffer. Se et eksempel i bilag B.
Er der mĺlt mange enkeltstoffer kan forskellige multivariate teknikker eksempelvis principal komponent analyse (PCA) , Min/Max Autocorrelation Factors (MAF) anvendes til at beskrive korrelation af de stoffer der er interessante (Nielsen 1994, Andersen 1994). Derved kan man reducere dimensionen af datasćttet. Teknikkerne beregner nye variable, der er linear kombinationer af de oprindelige mĺleparametre. Disse nye uafhćngige variable kan sĺ anvendes i en spatiel analyse. Anvendelse af disse metoder samt tolkningen resultaterne břr foretages af statistikere og miljř/forurenings eksperter i fćlleskab.
3.2 Spatiel statistik (geostatistik)
Der findes forskellige statistiske metoder, der estimerer den geografiske varians/korrelationsstruktur udfra mĺlingerne og udnytter denne i interpolationen mellem mĺlepunkterne samt beregner usikkerheden pĺ interpolationsresultatet.
Disse metoder antager og udnytter, at observationer i nćrheden af hinanden er korrelerede mere korrelerede en observationer langt fra hinanden (modsat standard statistiske analyser der antager at observationerne er uafhćngige).
3.2.1 Geografisk korrelation
Den geografiske varians/korrelationsstruktur i data kan beskrives pĺ forskellig vis. To principielt forskellige mĺl anvendes hyppigt.
- Det simple mĺl tester om data kan antages at vćre uafhćngige af geografien (afstande) og er derfor ikke umiddelbart anvendeligt til beregninger.
- Det mere komplicerede mĺl kvantificerer variansens (eller korrelationens) afhćngighed af afstanden.
ad 1)
Som test for geografisk uafhćngighed kan anvendes Moran’s I , der tester hypotesen om "ingen spatiel korrelation" (Cliff and Ord, 1973, 1981; Anselin 1995). Moran’s I beskriver korrelationen mellem "naboer". En stor vćrdi af Moran’s I betyder positiv korrelation og en lille (negativ) vćrdi betyder negativ korrelation. Det kan testes om (Moran’s I ) korrelationen er signifikant. Resultatet af analysen er udelukkende et ja/nej svar til om der er spatiel korrelation eller ej, der fremkommer ikke noget udtryk der beskriver korrelationens afhćngighed af afstanden mellem observationerne
ad 2)
Variogrammer er hyppigt anvendt til at kvantificere den geografiske afhćngighed. Der knytter sig normalt 3 parametre til et variogram. De beskriver egenskaber ved variogrammet og betegnes nugget, sill og range (Cressie 1991, Ripley 1988, Diggle 1983).
Nugget er en sum af flere komponenter der med en snedig forsřgsplan kan adskilles, den bestĺr af mĺleusikkerheden samt den variation der er mellem to prřver taget meget tćt pĺ hinanden. Mĺle usikkerheden kan estimeres ved at lave flere bestemmelser pĺ samme prřve og variationen mellem prřver med meget lille indbyrdes afstand kan estimeres ved at udtage prřver med meget lille afstand.
Sill er den maksimale variation, det vil sige den variation der er i data stammende fra mĺlepunkter med sĺ stor indbyrdes afstand at de er uafhćngige.
Denne afstand hvor mĺlingerne ikke lćngere er korrelerede, dvs. uafhćngige kaldes range.
Forholdet (Sill - Nugget)/Nugget er af stor betydning for den videre anvendelse af variogrammet til for eksempel kriging. Variogrammet beregnes ved at inddele afstanden mellem observationerne i en rćkke intervaller. Dernćst beregnes variansen mellem alle observationer i det pĺgćldende interval. Disse varianser plottes derefter mod afstanden mellem observationer som skitseret i nedenstĺende Figur 4, Nugget, Sill og Range er ligeledes skitseres.
Det er nćrliggende at tilpasse (fitte) en kurve til punkterne i variogrammet. Der eksisterer adskillige variogrammodeller – de oftest anvendte er en gaussisk, eksponentiel eller sfćrisk funktion (Cressie 1991, Ripley 1983, Diggle Nielsen 1994, Andersen 1994). Parametrene der beskriver disse kurver er netop nugget, sill og range. Der anvendes ofte en vćgtet mindste kvadraters metode til at fitte disse funktioner. Der vćgtes ofte med antallet af punkter der ligger til grund for de enkelte varians punkter.
Her břr det pĺpeges at den tilpassede kurve og dermed estimationen af nugget, sill og range vil vćre afhćngig af valget af antal intervaller. Den tilpassede kurve udgřr nu det bedste bud pĺ variations afhćngighed af afstanden mellem observationer. Den tilpassede variogramkurve benyttes som en vćgt i interpolationsmetoden kaldet kriging. Det er altsĺ den aktuelle geografiske variation som data udviser der bestemmer med hvilken vćgt de skal indgĺ i analysen, modsat standard interpolationsmetoder som "Nćrmeste nabo" eller Euklidisk afstand" hvor der ikke tages hensyn til den struktur data udviser.
Stejlheden af variogrammet beskriver hvor hurtigt variansen/korrelationen ćndrer sig
Variogrammet břr estimeres i forskellige retninger, sĺ udelukkende mĺlepunkter i en vis retning kommer i betragtning eks. (0° ,45° ,90° ,135° ). Endvidere kan omrĺdet inddeles i delomrĺder og variogrammet kan estimeres indenfor hvert delomrĺde. Inddeles omrĺdet i en rćkke delomrĺder bliver det naturligvis pĺ bekostning af antallet af observationer i omrĺdet.
Den vćsentligste indvending mod at anvende traditionel kriging som interpolationsmetode er at variogrammet er afhćngig af střrrelsen af de valgte intervaller. Dette diskuteres yderligere i efterfřlgende afsnit om estimation og kriging.
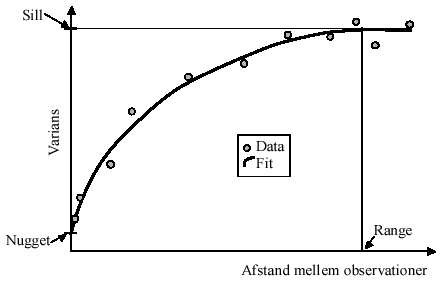
Figur 4
Teoretisk variogram
Theoretical variogram
3.2.2 Estimation og kriging
I dette afsnit vil der blive prćsenteret to forskellige mĺder ( interpolationsmetoder) at estimere niveauet af ét enkelt stof inden for et geografisk omrĺde, her betegnet Kriging (Cressie 1991, Ripley 1988, Diggle 1983, Nielsen 1994, Andersen 1994) og Likelihood (Diggle and Ribeiro 2000, 2001; Christensen, Diggle and Ribeiro 2000, 2001). De to metoder er skitseret i det fřlgende
- Vćlg en maksimal afstand og inddel afstanden i antal intervaller.
- Estimer variogrammet, dvs. variationen indenfor hvert afstandsinterval
- Estimer parametrene i en variogramfunktion (nugget, sill og range).
- Benyt variogramfunktionen i kriging til at estimere niveauet
- Benyt "kriging standard error" til at beregne et konfidensinterval for estimatet
Resultatet er at der pĺ basis af de mĺlte vćrdier beregnes koncentrationsintervaller for forureningen (enkeltstoffer) over omrĺdet som helhed.
I simpel/ordinćr kriging prćdikteres vćrdierne udelukkende baseret pĺ variogrammet, hvor data vćgtes i forhold til den fittede variogram funktion. Dvs. variogrammet benyttes til at forudsige bĺde global og lokal variation.
I universel kriging fittes en n'te grads model til data og der foretages ordinćr kriging af residualerne, addition af disse giver den predikterede vćrdi. n'te grads modellen beskriver den globale variation (eks. trend) og kriging af residualerne beskriver den lokale variation (afvigelser fra trenden).
Et specialtilfćlde af universel kriging er ordinćr kriging hvor n=0, dvs et niveau samt kriging af residualerne. Usikkerheden pĺ prediktionen i universel kriging er usikkerheden pĺ kriging af de spatielt korrelerede residualer adderet til usikkerheden pĺ n'te grads polynomiet. Der benyttes almindelige statistiske betragtninger til at vurdere hvordan parametrene (orden af polynomiet), skal vćlges (Venables and Ripley 1999, Cressie 1991)
- Vćlg en variogram funktion
- Estimer niveauet samt parametrene i variogramfunktionen (nugget, sill og range).
- Benyt "standard error" til at beregne et konfidensinterval for estimatet
3.2.3 Valg af metode
Udfra en statistisk betragtning břr Likelihood metoden vćlges idet den er uafhćngig af valg af intervaller og er derfor at foretrćkke. Desvćrre er denne metode ikke sĺ velkendt eller anvendt af andre end statistikere (Diggle and Ribeiro 2000, 2001; Software geoR).
Udfra en praktisk synsvinkel og med den store mćngde programmer der kan estimere semivariogrammer og foretage kriging vil denne metode vćre at foretrćkke
Der vćlges den variogram funktion der ud fra almindelige statistiske betragtninger giver det bedste fit.
En ofte anvendt metode at slette enkelte datapunkter og dernćst estimere dem med kriging og kigge pĺ forskellen mellem det mĺlte og det estimerede (Cressie 1991, Andersen 1994).
4. Diskussion
Som beskrevet i afsnit 2 er designet afhćngig af den hypotese, der er generet om den diffuse jordforureningsudbredelse samt formĺlet med analysen. Den vćsentligste forskel ligger i om formĺlet er at estimere niveauet i hele det geografiske omrĺde eller der udelukkende řnskes en sandsynliggřrelse af om en given grćnsevćrdi overskrides.
Det vil til tider kunne betale sig at lave et faseopdelt undersřgelsesprogram med henblik pĺ et dynamisk forsřgsdesign som skrćddersyes/optimeres trinvis. Dette ville givetvis have vćret fornuftigt i eksemplet gennemarbejdet i bilag B.
Det er en fordel at udpege delarealer, hvor der kan forventes kritiske vćrdier, idet dette giver information om det maksimale niveau af den observerede střrrelse.
4.1 Valg af software
Haves data i et GIS (MAPINFO, ARCVIEW, IDRISI) kan de tilhřrende spatielle add-in’s benyttes til de geostatistiske analyser. Pĺ web adressen http://www.ai-geostats.org/ er en glimrende oversigt over alverdens forskellige programmer, samt henvisninger til litteratur.
Til analyserne i bilag B er anvendt GeoR: http://www.maths.lancs.ac.uk/~ribeiro/geoR.html
En lřftet pegefinger: Pas pĺ automatiserede interpolationsprogrammer idet disse ikke altid giver mulighed for at vurdere de underliggende forudsćtninger.
5. Referenceliste
5.1 Litteratur
Andersen J.S. (1994). Flerdimensionale rumligt korrelerede forureningsdata, IMM, DTU. Eksamensprojekt 1994-28, ISSN 0909-6256.
Anselin L. (1995). Local indicators of Spatial Association – LISA. Geographical Analysis.; 27 (2):93-115.
Christensen, O.F. Diggle P.J. and Ribeiro J.R. (2001). Analysing positive-valued spatial data: the transformed Gaussian model. I Monestiez, P., Allard, D. and Froidevaux (eds), GeoENV III - Geostatistics for environmental applications. Quantitative Geology and Geostatistics, Kluwer Series, 11, 287--298.
Cressie N.A. (1991). Statistics for Spatial Data Wiley and Sons.
Diggle P.J. (1983). Statistical analysis of spatial point patterns. Academic press, London.
Diggle P.J. and Ribeiro J.R. (2000). Model-based geostatistics. Caxambu: Associaçăo Brasileira de Estatística. (14ş SINAPE - Simpósio Nacional de Probabilidade e Estatística).
Diggle P.J. and Ribeiro J.R. (2001). Bayesian inference in Gaussian model-based geostatistics. Geographical and Environmental Modelling (to appear)
Nielsen, A.A. (1994). Analysis of Regularly and Irregularly Sampled Spatial, Multivariate, and Multi-temporal Data. Ph.D. Thesis No. 6, Department of Mathematical Modelling, Technical University of Denmark
Cliff A.D. and Ord J.K. (1973). Spatial autocorrelation. London: Pion Ltd..
Cliff A.D. and Ord J.K. (1981). Spatial processes, Models and applications. London: Pion Ltd.
Ribeiro JR, and Diggle PJ. (1999). geoS: A geostatistical library for S-PLUS. Technical report ST-99-09, Dept of Maths and Stats, Lancaster University.
Ripley B. D. (1988) Statistical inference for spatial processes. Cambridge University Press. Cambridge
Venables W.M. and Ripley B. D (1999). Modern applied statistics with S-plus. 1999 Springer, New York.
5.2 Software
http://www.ai-geostats.org/
http://www.maths.lancs.ac.uk/~ribeiro/geoR.html