|
Pilotbenchmarking af miljøtilsynet 8 Vejning8.1 Den simple vejemetode - tabelvejning I forbindelse med følgegruppemøderne har der været ønske om at kunne tage højde for forskellene, som måtte skyldes forskelle i virksomhedssammensætningen i de enkelte kommuner og amter. Der eksisterer en række vejemetoder, som kan anvendes til at korrigere for sådanne forhold. I det følgende beskrives tre forskellige metoder ved hjælp af eksempler.
Løsningerne skitseres særskilt, men de kan også kombineres, så det bedste fra alle verdener opnås. 8.1 Den simple vejemetode – tabelvejningDen simple løsning er at udregne en forventet fordeling på kategori 1, 2 og 3 virksomheder i en kommune ud fra virksomhedssammensætningen i kommunen og den gennemsnitlige nationale fordeling af virksomheder i de tre kategorier. Metoden kan anvendes til at konkludere, om kommunen har en tendens til at klassificere virksomheder anderledes (f.eks. tendens til at placere relativt flere i kategori 2) end resten af kommunerne. Metoden kan både bruges i forhold til kommuner og amter. Metoden er eksemplificeret nedenfor. Tabellen nedenfor viser, at kommuner, som eksempelvis har forholdsmæssigt mange autoværksteder, må forventes at have flere kategori 3 virksomheder end en kommune, som har mange godkendelsespligtige virksomheder. Tabel 9: Den nationale fordeling fra pilotbenchmarking
Nedenstående tabel viser virksomhedssammensætningen i en fiktiv kommune. Det fremgår, at kommunen totalt set har markant flere kategori 1 og 3 virksomheder end landsgennemsnittet. Skyldes dette, at kommunen har en helt speciel virksomhedssammensætning? Tabel 10: Fordeling i fiktiv kommune
Dette kan afgøres ved at sammenligne det forventede antal kategori 1 – 3 virksomheder, ud fra den viden man har om fordelingen på type af virksomhed (IPPC virksomhed, anmeldevirksomheder mv.) i kommunen. Logikken er den simple, at udregne antallet af virksomheder i hver kategori ud fra landsgennemsnittet. Dette giver derefter et totalt forventet antal i hver kategori. Dette forventede tal kan herefter sammenlignes med det faktiske. Et eksempel på resultatet af denne simple udregning ses nedenfor: Tabel 11: Forventet fordeling af virksomheder ud fra national fordeling
Som det fremgår af udregningen, forventes det, at der er 9,76 autoværksteder, som er kategoriseret som kategori 1 virksomheder i kommunen. Dette er fundet ved at tage antal autoværksteder i kommunen (61) og gange med 16 %, som er den andel af autoværksteder, der gennemsnitligt på landsplan er kategori 1 virksomheder. Vi får altså 0,16 * 61 = 9,76. Ud fra ovenstående tabel, kan man udregne den procentvise forskel (tabel ikke medtaget her). Herefter kan man sammenligne de enkelte fordelinger med de faktiske fordelinger. Dette er gjort i tabellen ovenfor. Tabel 12: Forskel faktisk fordeling minus forventet fordeling
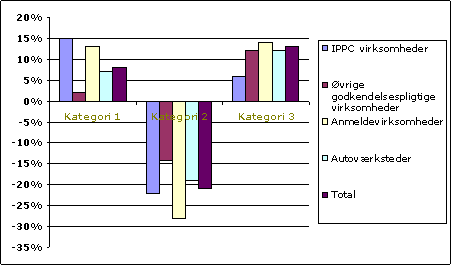
Heraf fremgår det, at der i kommunen er færre kategori 2 virksomheder, end man skulle forvente. Dette skyldes, at der konsistent for alle typer af virksomheder er færre virksomheder, der er i denne kategori. Specielt er der få anmeldevirksomheder i denne kategori. Konklusionen må med andre ord være, at den store andel af kategori 1 og kategori 2 virksomheder, som sås i tabel 2, ikke skyldes en speciel virksomhedsfordeling, men snarere at kommunen konsistent for alle virksomhedstyper er mindre tilbøjelig til at kategorisere virksomhederne som type 2 virksomheder. Tallene for den enkelte kommune kan naturligvis også repræsenteres grafisk. Figur 20: Forskel faktisk fordeling minus forventet fordeling
Metoden kan, ud over at sammenligne kategorisering af virksomheder, anvendes til at sammenligne:
8.2 KlyngevejningVed denne metode laves 10-20 klynger af kommuner, som anses for at have sammenlignelige rammevilkår. Det er f.eks. denne metode, som anvendes i de såkaldte ECO-nøgletal, som de fleste kommuner kender. Et eksempel på en klynge kunne være at samle kommuner, som har under 10.000 indbyggere, mange landbrugsvirksomheder, og som har lagt tilsynsopgaven ud til et miljøsamarbejde. Fordelen ved denne metode er, at kommunerne kan sammenligne deres indberetninger direkte op imod hinanden, da beregninger ikke er nødvendige. Dermed vil de rapporterede tal til sammenligning svare til dem, som er eksemplificeret i pilotbenchmarkingen. Beregningerne er så at sige foretaget i klyngedannelsen. Dermed kan kommunerne selv identificere benchmarkingpartnere, som de kan arbejdere videre med i mere detaljerede undersøgelser af årsagerne til de identificerede forskelle. Klyngedannelsen kan foretages ud fra nogle bløde overvejelser eller ud fra hårde data. De bløde overvejelser kunne indeholde betragtninger om, hvilke kommuner den enkelte kommune mener at have noget til fælles med. Ofte har geografisk placering stor betydning. Til supplering af denne subjektive vurdering eller helt alene, kunne man lave en klyngeanalyse. En klyngeanalyse gennemføres enkelt forklaret ved, at man vælger en række klassificeringsvariabler. Derefter gennemføres analysen, hvor det drejer sig om at opdele i et specificeret antal grupper, hvor de indbyrdes forskelle minimeres. Det kunne eksempelvis være kommunestørrelse, erhvervssammensætning, urbaniseringsgrad etc., som medtages. Metoden er ikke velegnet til amter, da der er meget få enheder, som kan grupperes. En mere velegnet metode ville være tabelvejning. 8.3 ResidualanalyseResidualanalyse er i princippet en forfinet form for tabelvejningen, som er beskrevet ovenfor. Forfinelsen består i, at det er muligt at inddrage mange flere variable, fordi metoden er baseret på statistisk regression. I tabelvejningen vejes der 'kun' for forskelle i virksomhedssammensætning. Hvis statistisk regression anvendes, er der ikke samme begrænsning. Ulempen er, at der skal laves en regressionsmodel for hver enkelt indikator, som ønskes sammenlignet:
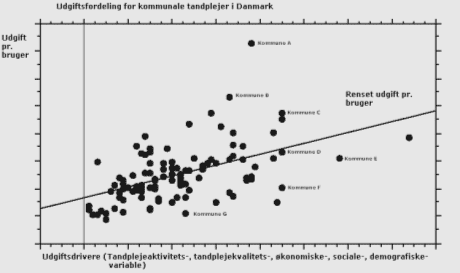
Det er ikke muligt at konstruere et eksempel med det grænsede datamateriale. Metoden bruges blandt andet også til benchmarking af folkeskoler, tandpleje, kommunal aktivering. Nedenfor illustreres metoden med en sammenligning af ressourceforbrug. For hver af kommunerne er der beregnet et forventet ressourceforbrug pr. virksomhed, som sammenholdes med det faktiske ressourceforbrug pr. virksomhed. Det rensede ressourceforbrug giver et bud på, hvad en kommunes udgift kan forventes at være, når en kommunes specifikke virksomhedssammensætning, andel skrivebordstilsyn osv. bliver indoptaget i analysen. Metoden er langt mere retvisende end simple nøgletalssammenligninger (f.eks. ECO nøgletal), hvor der laves sammenligninger af udgifter uden hensyntagen til typen af virksomheder og øvrige rammevilkår. Figuren nedenfor illustrerer princippet for metoden anvendt på tandplejeområdet.
Figuren viser sammenhængen mellem en række udgiftsdrivere og udgiften pr. bruger i en række kommuner. Linien, der går tværs igennem prikkerne, viser den rensede udgift for de enkelte kommuner. Prikkerne illustrerer kommunernes faktiske udgift pr. bruger. I dette eksempel ligger kommune D lige på den rensede udgift, mens kommune E, F, G bruger færre ressourcer end forventet og kommune A, B, C
|