Strategier for kortlægning af diffus jordforurening i byområder
5 Databehandling
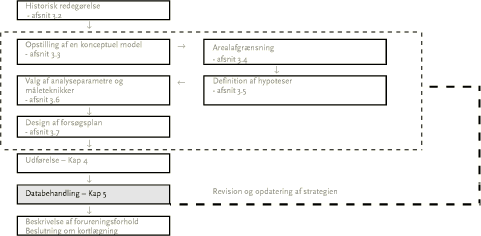
Ved databehandlingen vurderes, om hypoteserne vedrørende forureningsforhold kan dokumenteres. Data fra den historiske redegørelse og evt. tidligere data medtages i databehandlingen.
Der er tre formål med databehandlingen:
- at kontrollere, at der er overensstemmelse mellem den konceptuelle model og de aktuelle forureningsdata
- at vurdere, om der er indsamlet tilstrækkelige data
- at vurdere, om der er et tilstrækkeligt grundlag for kortlægning på Vidensniveau 2
Da formålet med projektet er at forenkle kortlægningen af arealer med diffus jordforurening, skal undersøgelsesstrategierne dokumentere, at der er en høj grad af sikkerhed for, at “et areal som helhed er forurenet”, og at man kan interpolere mellem målepunkter og være sikker på, at jorden her også er forurenet. Dette kræver bevis for “et sammenhængende forureningsmønster og en sammenhængende arealanvendelsesmæssig historik”, samt for, at arealet er forurenet (dvs. at et flertal af målinger overskrider jordkvalitetskriteriet, JKK).
Derfor er det vigtigt at kontrollere, at der er overensstemmelse mellem den konceptuelle model og de aktuelle forureningsdata. Endvidere kan den geostatistiske databehandling anvendes til vurdering af sandsynligheden for overskridelse af en vilkårlig koncentrationsgrænse, f.eks. et afskæringskriterium (ASK) eller en anden grænseværdi.
Som grundlag for databehandlingen anbefales anvendt metoder fra en amerikanske US EPA rapport om dataanalyse /14/.
5.1 Vurdering af ensartede forureningsniveauer
For diffus jordforurening, som kan beskrives med bidragsmodellen, fyldjordmodellen eller overflademodellen vil der kunne forventes en ensartede, eventuel varierende og tilfældig belastning af topjorden.
I datarapporten for kulturlag er der angivet eksempler på databehandling /4/.
Deskriptiv statistik
I datarapporten om kulturlag /4/ er der givet en detaljeret beskrivelse af databehandlingen, og redegjort for datahåndtering - bl.a. beregning af gennemsnit og median - i tilfælde af kun få datapunkter, og af prøver, hvor intet er påvist.
Såfremt der er flere end 7 værdier anbefales det, at følgende værdier for alle parametre i alle dybder beregnes og angives, jf. tabel 5.1:
- antal data
- minimum, median, maksimum
- fraktiler (f.eks. 10, 25, 50 75 og 90%)
- gennemsnit
Overskridelse af henholdsvis JKK og ASK kan vises med en markering, således at man f.eks. direkte kan aflæse, om 90% af dataene (0,9 fraktil) er under eller over JKK, eller om forureningsniveauet stiger eller falder i dybden.
| Parameter | Dybde | Antal pkt. |
min | Fraktiler | max | gns. | JKK | % >JKK |
ASK | % >ASK |
||||
| m | 0,1 | 0,25 | 0,5 | 0,75 | 0,9 | |||||||||
| Bly | 0,1 | 51 | 23 | 44 | 140 | 360 | 530 | 590 | 2700 | 390 | 40 | 90 | 400 | 41 |
| 0,3 | 41 | 18 | 35 | 180 | 370 | 440 | 500 | 620 | 310 | 88 | 29 | |||
| 0,55 | 11 | 19 | 140 | 260 | 280 | 340 | 360 | 380 | 270 | 91 | ||||
| 1,05 | 7 | 78 | 93 | 130 | 140 | 180 | 330 | 510 | 210 | 100 | 14 | |||
i.p.: ikke påvist gns.: gennemsnit
| Overskridelse af JKK – Jordkvalitetskriteriet /15/. | |
| Overskridelse af ASK – Afskæringskriteriet /15/. |
Tabel 5.1 Eksempel af en tabel over resultater (mg/kg TS).
Example of a table with results.
Hvis gennemsnittet og 0,5 fraktil (medianværdien) er forskellige, er der tale om en asymmetrisk fordeling – men hvis der f.eks. findes enkelte høje værdier, vil gennemsnittet være højere end median. Gennemsnittet vurderes ikke altid at være repræsentativt for diffust forurenede arealer, idet et gennemsnit i teorien kun kan anvendes til at beskrive data, der er normalfordelte (en fordeling af høje og lave værdier, der er symmetriske omkring en gennemsnitsværdi). Data kan desuden vises som et fraktilplot, jf. figur 5.1, hvor alle datapunkter vises.
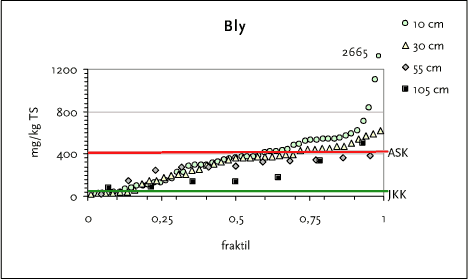
Figur 5.1 Eksempel på et fraktilplot for bly
Example of a quantile plot for lead
Hvis dataene er normalfordelte (symmetriske omkring gennemsnittet), vil et fraktilplot have en S-form med en relativt flad sektion i midten. Derimod vil en stor spredning i koncentrationsniveauet betyde, at kurven stiger brat. Hvis dataene er asymmetriske med en lang hale (høje værdier) til højre, ses en stejl stigning i den øverste højre del af kurven i forhold til den nederste venstre del, jf. figur 5.1.
Desuden kan der tegnes tematiske kort som viser koncentrationer i de enkelte målepunkter. Kortene illustrerer eventuelle tendenser til stigende eller faldende forureningsniveauer over undersøgelsesarealet, jf. figur 5.2.
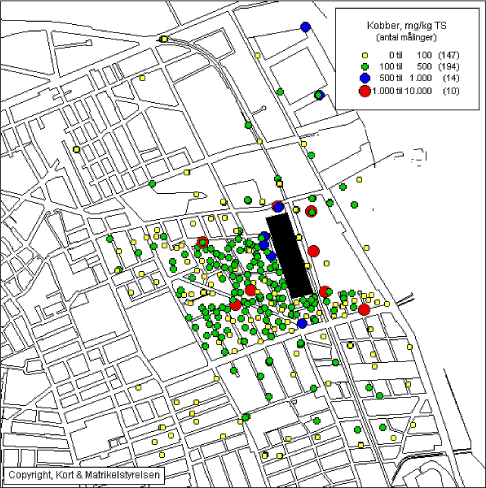
Figur 5.2 Kort over blymålinger i 10 cm’s dybde
Map showing lead measurements in 10 cm’s depth
Hvis et sæt prøver repræsenterer punkter fra en normalfordeling, kan resultaterne beskrives ved gennemsnit og varians (symmetrisk spredning af data på hver side af gennemsnittet). Et sæt prøver fra en normalfordeling vil i praksis være begrænset til en endelig størrelse og vil derfor være t-fordelt. Histogrammerne for såvel en normalfordeling som t-fordeling illustreres i figur 5.3.
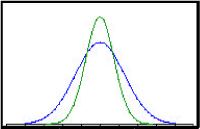
Figur 5.3 Histogrammer for en normal- og en t-fordeling
Histograms showing a normal and a t-distribution
Miljødata viser derimod ofte en asymmetrisk fordeling af værdier med en lang hale til højre på fordelingen (høje værdier), jf. figur 5.4. Dette betyder, at forudsætningen ikke er opfyldt for mange statistiske standardtests. Da funktionen Y=ln(X) for lognormale data er normalfordelt, kan en logaritme- transformation af værdierne betyde, at dataene bliver tilnærmelsesvis normalfordelte. En sådan transformation er nødvendigt, hvis der skal anvendes statistiske tests eller geostatistiske databehandlinger, idet disse forudsætter, at dataene er normalfordelt.
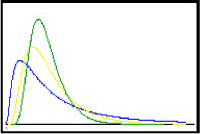
Figur 5.4 Histogrammer for lognormalfordelinger
Histogram showing lognormal distributions
Derfor bør det vurderes om dataene er normal- eller lognormalfordelte ved en Shapiro-Wilk (W) test. Testen bygger på korrelationen imellem fraktilerne i en standard normalfordeling samt på de rangordnede værdier i datasættet. Den er dermed direkte relateret til det Q-Q-plot, der er beskrevet herunder. Nulhypotesen for Shapiro-Wilk testen er, at den sande fordeling er en normalfordeling. Sandsynligheden (p) for det aktuelle udfald af hver test angives. Ved p< 0,05 er testen signifikant og nulhypotesen forkastes, dvs. at datafordelingen ikke er normalfordelt.
Der kan desuden anvendes visuelle grafiske teknikker (fraktilplot, histogram, eller Q-Q-plot, jf. figur 5,1, 5.5 og 5.6). For et normal-Q-Q-plot plottes data i forhold til fraktilerne i en normalfordeling. Dette svarer til at plotte data på normalfordelingspapir. Her er blot som x-akse anvendt teoretiske variabler i en standard normalfordeling frem for fraktiler. Disse akser er lineære og kan bedre håndteres af et elektronisk medie. For en ideel normalfordelt variabel vil punkterne ligge på en ret linie. Ekstreme værdier eller såkaldte “outliers” - afvigende punkter - kan identificeres ved deres beliggenhed langt fra denne linie. En prøve fra en normalfordeling vil i praksis være begrænset til en endelig størrelse, og vil derfor være t-fordelt og udgøre en svag s-form i plottet. En udpræget s-form betyder imidlertid, at fordelingen har længere haler end normal- eller t-fordelingen. En U-form betyder, at fordelingen er skæv i forhold til en normal- eller t-fordeling.
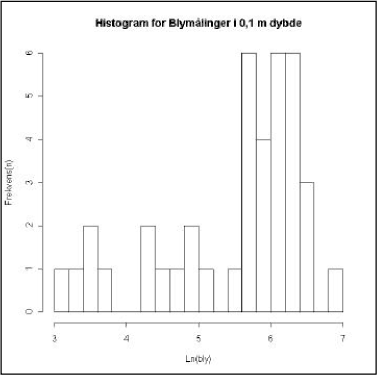
Figur 5.5 Eksempel på et histogram for logaritme-transformerede værdier for bly
Example of a histogram for the log transformed values for lead
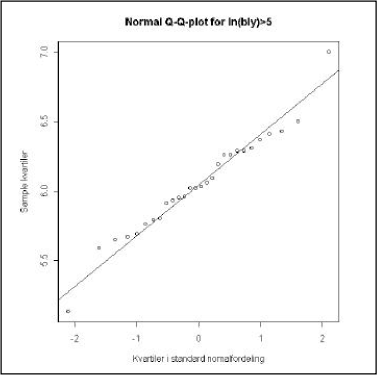
Figur 5.6 Eksempel på et Q-Q-plot for logaritmetransformerede blydata
Example of a quantile-quantile plot of a subset of the log transformed data
Ved at identificere afvigende punkter kan disse vurderes i henhold til deres fysiske position i undersøgelsesarealet og delområdets historik. Herefter kan det overvejes at fjerne et datapunkt eller at opdele dataene i subgrupper, svarende til et mindre delområde med et mere sammenhængende forureningsniveau.
Til vurdering af, hvorvidt data i f.eks. forskellige dybder eller fra forskellige delområder er forskellige fra hinanden, anbefales en non-parametrisk test, “Wilcoxon Rank Sum Test”, såfremt fordelingerne ikke er normalt fordelt. Til sammenligning af gennemsnitsværdier kan der for normal eller lognormalfordelte data anvendes en t-test. Sandsynligheden for overskridelse af JKK og ASK kan beregnes på basis af t-fordelingen.
Den deskriptive statistik giver et overblik over forureningsniveauet for de enkelte områder, men siger ikke noget om rumlige (spatielle) tendenser (f.eks. at forureningsniveauet aftager i en vis retning).
Geostatistik
Den geostatistiske analyse gør det muligt at estimere koncentrationerne over et område ved hjælp af kriging, samt usikkerheden af estimatet. Ligeledes kan sandsynligheden for, om jorden på et givet sted i området ligger over jordkvalitetskriteriet og under afskæringskriteriet beregnes. Men det er dog ikke alle områder, der er egnet til geostatistisk analyse. For eksempel kan det være svært at påvise spatiel korrelation på arealer, der er mindre end 0,2 km² og hvor der er indsamlet mindre end 40 datapunkter, især for arealer med stor inhomogenitet.
Geostatistisk databehandling beregner forskelle i variansen mellem dataværdier, lokaliseret i forskellig afstand af hinanden. Alle data inden for forskellige afstandsintervaller (lag), f.eks. 0 - 25, 25 - 50, 50 - 75 m osv. sammenlignes parvis. Herefter laves et XY-plot af forskellen i variansen mod afstanden. Et XY-plot er vist i figur 5.7. Figuren kaldes et eksperimentalt semivariogram. Ved at vælge forskellige lagintervaller, ændres det eksperimentale semivariograms udseende. Det er således vigtigt at foretage følsomhedsberegninger og vælge realistiske lagintervaller i forhold til områdets størrelse og forventningen om forureningsspredningen.
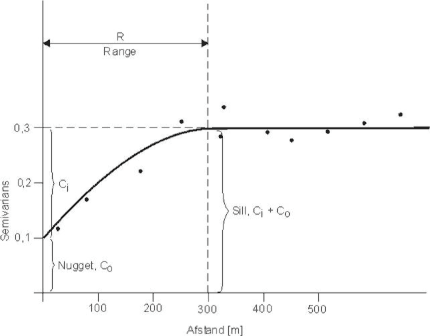
Figur 5.7 Et semivariogram
A semivariogram
Geostatistikken bygger på, at målinger på prøver, der er udtaget tæt på hinanden, er mere ensartede end målinger på prøver, der er udtaget med større afstand. Målingerne siges, at være “korrelerede” inden for en vis afstand. Denne afstandskorrelation betegnes i det følgende som spatiel korrelation.
Det kan i praksis ofte være vanskeligt at afgøre, om den undersøgte parameter opfylder de forudsatte antagelser og betingelser for den geostatistiske analyse. Det gælder ikke mindst antagelsen om normalfordelingen.
Normalfordelingskravet kan undersøges med de metoder, der er nævnt i ovenstående afsnit om anvendte deskriptive metoder. Som det ofte er tilfældet med mange naturlige stokastiske variabler, er geokemiske data ofte lognormalfordelte. Det betyder, at det er nødvendigt at logaritme-transformere de pågældende parametre før analysen. Den estimerede koncentration og konfidensintervallet skal derfor tilbagetransformeres, før de kan anvendes ved kortlægning. Ved denne procedure introduceres en uundgåelig bias, der ses som et skævt konfidensinterval, med en forholdsvis høj øvre grænse.
På trods af logaritmisk transformering af data forekommer der på grund af ekstreme værdier i flere tilfælde afvigelser fra normalfordelingen. I sådanne tilfælde kan datafordelingen undersøges isoleret i de forskellige delområder. Såfremt betingelserne for en normalfordeling er tilnærmelsesvis opfyldt i disse delområder, anses det for forsvarligt at udføre analysen for området som helhed.
Det kan ligeledes være nødvendigt med en særskilt undersøgelse af semivariogrammerne inden for forskellige delområder, idet variogrammet kan ændre karakter inden for det undersøgte område.
Validering af den spatielle korrelation, som anvist af den valgte teoretiske model, kan testes med Moran's I-test. Testen er imidlertid tidskrævende og ikke særlig følsom, hvorfor der oftest anvendes grafiske metoder.
Flere simple plot og grafiske afbildninger er relevante forud for konstruktionen af semivariogrammet. Der bør foretages følgende aktiviteter:
- granske datamaterialet på kort
- evaluere fordelingerne i forhold til normalfordelingen
- identificere eventuelle ekstreme værdier
Scatterplot af kvadrerede differencer plottet mod afstanden mellem punktobservationer kan bidrage til et grundlæggende og simpelt billede af den spatielle korrelation, samt med informationer om den geografiske skala for variationen. Hvis der er en spatiel korrelation, må det forventes, at de kvadrerede differencer vokser med afstanden imellem prøvepunkterne. Et scatterplot illustreres i figur 5.8.
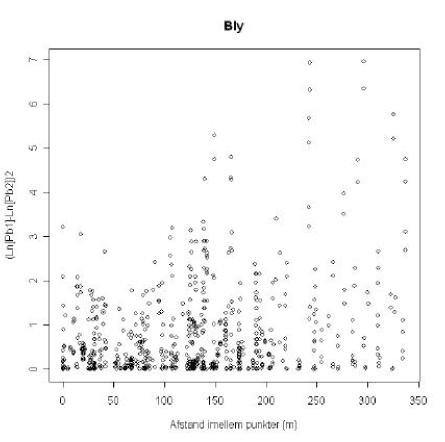
Figur 5.8 Eksempel af et scatterplot af afstande og kvadrerede differencer imellem logaritmisk transformerede koncentrationer i parvise prøvepunkter for bly.
Example of a scatterplot of distance and squared difference of the log transformed concentrations in pair wise sampling points for lead.
Ved spatiel korrelation må der forventes en positiv korrelation imellem de kvadrerede differencer og afstande. En sådan korrelation kan evt. testes med Spearmans korrelationskoefficient, der er velegnet til at vurdere voksende (monotone) stokastiske funktioner. Spearmans korrelationskoefficient-test er en såkaldt “fordelingsfrit” rangtest.
I figur 5.9 vises et aktuelt semivariogram fra afprøvning af strategierne i testarealerne.
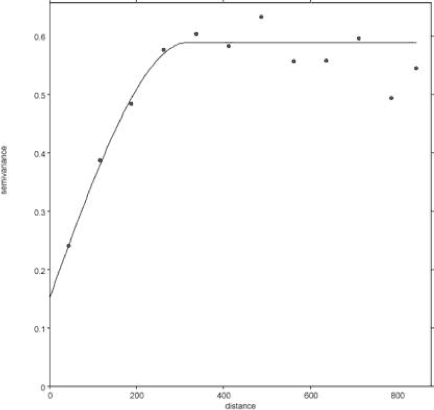
Figur 5.9 Eksempel af et semivariogram for logaritme-transformerede blydata.
Example of a semivariogram fro log transformed lead data
Ved evalueringen af variogrammet er det især vigtigt at evaluere de punkter i semivariogrammet, som viser større eller mindre hop eller dyk i estimerede semivarianser, idet disse også kan påpege særlige spatielle forhold på det undersøgte område (en vej, et areal med andet forureningsmønster m.fl.). Disse afvigelser er dog kun relevante, hvis de ses inden for den korrelerede range for varians (mindre end 300 m i figur 5.7). Større eller mindre hop eller dyk i estimerede semivarianser ved større “lag-afstand” end “range” kan snarere skyldes tilfældige irrelevante forhold end de egenskaber, der er knyttet til den spatielle variation.
Det kan være vanskeligt at vurdere, om semivariansen er en entydigt voksende funktion, især når nugget udgør en betydelig del af den totale variation, som det ofte kan være tilfældet ved diffus jordforurening.
Endelig er det vigtigt at vurdere, hvilken indflydelse ekstreme værdier har på variogrammet. Den mest sårbare kombination er ekstreme værdier kombineret med ekstrem beliggenhed. Variogrammet kan evt. konstrueres både med og uden disse værdier.
Beregning af sandsynlighed som grundlag for kortlægning
Et væsentligt resultat af den statistiske databehandling er muligheden for beregning af sandsynligheden for, at:
- Jordkvalitetskriteriet er overskredet.
- Afskæringskriteriet ikke er overskredet.
Det vil sige, at man skal være sikker på disse forhold, før man kan tage beslutning om kortlægning på Vidensniveau 2 og videre tiltag.
Ad 1. Det er vigtigt at være sikker på, at der en vis sandsynlighed for, at jorden et givet sted i delområdet overskrider JKK, idet man ikke vil kortlægge på et ubegrundet grundlag.
Ad 2. Det er vigtigt at være sikker på, at der er en vis sandsynlighed for, at forureningsniveauet et givet sted i delområdet er mindre end afskæringskriteriet.
Det er i forbindelse med kortlægning af diffus jordforurening nødvendigt med en administrativ beslutning om, hvilken grad af sandsynlighed, der er nødvendig ved disse to beslutninger. Her skelnes mellem kortlægning på ejendomsniveau, hvor der indsamles data om en aktuel matrikel, og kortlægning af arealer med et fælles forureningsmønster.
Geostatistik anvendes til at beregne sandsynligheden for, om jorden på et givet sted i området ligger over jordkvalitetskriteriet eller under afskæringskriteriet. Men det er dog ikke alle områder, der er egnet til en geostatistisk analyse.
For eksempel kan der ikke umiddelbart anvendes en geostatistisk behandling for jordforurening, som kan beskrives med en liniemodel, dvs. diffus jordforurening fra trafikken, idet der vil være behov for flere målepunkter tæt på vejen end målt ved den anvendte strategi.
Den geostatistiske databehandling er opsummeret i figur 5.10.
Klik her for at se Figur 5.10.
Figur 5.10 Flowdiagram for geostatistik
Flow diagram for geostatistical analysis
Trin I: Er data normal- eller lognormalfordelte?
- Data skal være normalfordelte (eller lognormalfordelte) for at der kan foretages estimering af koncentrationsniveauer, konfidensintervaller eller sandsynlighed for overskridelser af JKK og ASK.
- Da dataene skal være normalfordelte, vil analysen være følsom over for afvigende data punkter, og for delområder, som viser stor heterogenitet, for skævhed i prøvetagningsplanen (f.eks. at der
indsamles flere punkter fra et delområde med et afvigende niveau) eller over for historiske begivenheder, som har påvirket kulturlaget.
- Hvis det ikke ved en dyberegående dataanalyse og opdeling i delområder iht. historik er muligt at beskrive, hvorvidt data er normal- eller lognormalfordelte (trin 1b) bør det vurderes, om der skal udtages
flere jordprøver (trin 1c).
- Arealer med stor heterogenitet findes især i områder med høj udnyttelsesgrad, lang historik og mange skiftende arealanvendelser, hvor der er foretaget diverse renoveringer og jordudskiftning. Disse typer arealer kan formentlig kun kortlægges ved med et større detaljeringsniveau, eventuelt helt ned på ejendomsniveau.
Trin 2: Analyse af spatiel korrelation
- Hvis variansen mellem punkter tæt på hinanden er af samme størrelse som mellem punkter med stor afstand, er der ingen spatiel korrelation.
- Der skal være et vist antal punkter inden for hvert afstandsinterval. Forskellige parametre kan optimeres i forbindelse med analysen, f.eks. lagafstanden, men det er vigtigt, at der er et tilstrækkeligt antal
datapunkter til at definere formen for det eksperimentelle semivariogram – der skal altså være et vist antal prøver. Antallet er til dels uafhængigt af arealets størrelse, men er ofte afhængigt af områdets
heterogenitet.
- På de ældre områder ses stor variation i koncentrationsniveauet. Dette betyder, at “nugget” – variansen inden for kort afstand tilnærmer sig værdien for “sill” – variansen mellem ukorrelerede punkter på
stor afstand. Dette giver meget støj i semivariogrammet og gør det svært at validere hvilken teoretisk modelligning, der skal anvendes til at beskrive data i det eksperimentale semivariogram. Dette betyder
også, at arealer uden spatiel korrelation kan vise ren “nugget” effekt, dvs. variansen mellem punkterne tæt på hinanden er samme størrelse som mellem punkter på stor afstand.
- Mens værktøjet til at lave krydssemivariogrammer er meget nyttigt, idet mange parametre kan evalueres samtidigt i forbindelse med simulering af den matematiske modelformulering, har det vist sig
problematisk at anvende cokriging. Ordinær kriging er anvendt til estimering af koncentrationsniveauer m.v.
- Scatterplot af kvadrerede differencer plottet mod afstanden mellem punktobservationer kan bidrage til et grundlæggende og simpelt billede af den spatielle korrelation, og med information om den
geografiske skala for variationen.
- Hvis en spatiel korrelation ikke kan påvises, vil den indledende databehandling i forbindelse med den geostatistiske analyse (efter inddragelse af historik, følsomhedsanalyse af afvigende målinger m.v.) ofte
indikere en rationel opdeling i delområder, og det kan undersøges, om data fra delområdet er normal- eller lognormalfordelte, jf. trin 1b. Ligesom i trin 1b, kan det vurderes, om der skal udtages flere
jordprøver.
- Hvis der ikke findes spatiel korrelation, kan alle data for et delområde behandles under ét, dvs. at der kan laves ét gennemsnit og ét konfidensinterval for hele delområdet, jf. trin 2b.
- Hvis der ikke findes spatiel korrelation kan der på grundlag af en fordelingsfunktion for normalfordeling foretages en beregning med arealets gennemsnit og standardafvigelse af sandsynligheden for, om
koncentrationsniveauet for hele delområdet under ét er højere end JKK og mindre end ASK.
- Logaritme-transformerede data eller ikke- transformerede data kan kun bruges, hvis de er normalfordelte. Dette kræver en omhyggelig afgrænsning af delområderne.
- Ligesom i trin 1c, kan det vurderes, om der skal udtages flere jordprøver for at forbedre datagrundlag i kritiske delområder.
Trin 3: Anvendelse af spatiel korrelation
- Når der er opnået en matematisk beskrivelse af, hvorledes de enkelte punkter er relateret til hinanden i forhold til deres indbyrdes afstand, kan man estimere koncentrationen og konfidensintervaller for
ethvert position i undersøgelsesarealet, jf. figur 5.11 taget fra /6/.
- Sandsynligheden for overskridelse af JKK og ASK kan i ethvert position beregnes på grundlag af den geostatistiske analyse, dvs. semivariogram-modellens estimat af såvel koncentration som
standardafvigelse, jf. figur 5.12 taget fra /6/.
- Alle usikkerhedsbidrag vil være indeholdt i denne sandsynlighed, der grundlæggende er et udtryk for, med hvilken sandsynlighed der vil kunne måles en koncentration over eller under jordkvalitetskriteriet,
hvis en prøve fra det pågældende sted blev udtaget og analyseret.
- Fordelen ved beskrivelsen af det spatielle (rumlige) forhold er, at koncentrationen beskrives som et kontinuum, og at det er muligt at håndtere mindre delområder, hvor der findes større eller mindre varians. Det vil sige, at estimatet for koncentrationsniveau og konfidensinterval samt sandsynligheden for, hvorvidt jorden på et givet sted i området ligger over jordkvalitetskriteriet, er baseret på de faktiske målinger i nærheden af stedet – altså den spatielle korrelation, idet målinger tæt på hinanden vil være mere ensartede end målinger foretaget på større afstande.
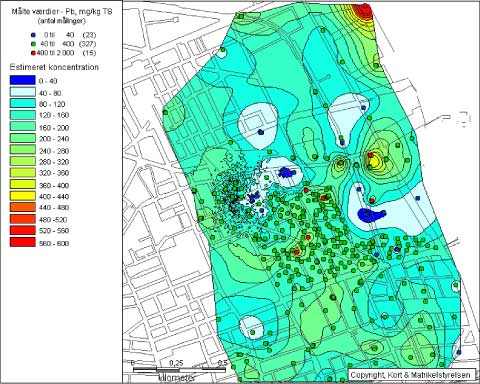
Figur 5.11 Estimat for Bly -koncentration. Koncentration i målepunkter er anvist med en farveskala. JKK er 40 mg/kg TS
Estimate for the concentration of lead. Soil guidance level is 401 mg/kg TS
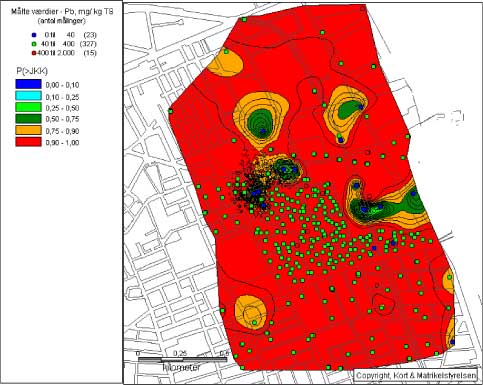
Figur 5.12 Sandsynligheden (p) for at en prøve udtaget et givet sted er større end JKK. Bly -koncentrationen i prøvepunkterne er angivet eksakt.
Probability (p) for a sample taken a certain position exceeds the soil guidance level. Lead concentrations in individual position are shown exact.
5.2 Vurdering af forurening som aftager med afstand til kilden
For diffuse jordforureninger, som kan beskrives med nedfaldsmodellen forventes det, at jordforureningen aftager i styrke med afstanden fra den oprindelige punktkilde, og at nedfaldsarealet vil være afhængigt af vindforhold samt topografiske og fysiske forhold ved punktkilden. Jordforureningen forventes at aftage i dybden.
Databehandling foretages efter samme principper som i afsnit 5.1, idet der kan anvendes geostatistisk databehandling. I datarapporten for industri er der angivet eksempler på denne type databehandling /6/.
For diffus jordforurening, som kan beskrives med liniemodellen forventes det, at jordforureningen aftager i styrke vinkelret på liniekilden. Jordforureningen forventes, at aftage i dybden.
Datapræsentation kan foretages efter samme principper som i afsnit 5.1, men i stedet for en geostatistisk databehandling anbefales en simpel grafisk præsentation af koncentrationerne i forhold til afstanden fra kilden. Det var i forbindelse med afprøvningen af strategierne ikke muligt at etablere en generel forklaringsmodel for koncentration og afstand fra veje, men en påvirkning fra trafikken ses typisk inden for en afstand af 10 – 20 m fra vejen med aftagende koncentrationer i dybden. I datarapporten for trafik er der angivet eksempler på denne type databehandling /5/.
Version 1.0 April 2004, © Miljøstyrelsen.