The Advisory list for self-classification of dangerous substances
2 Creation and use of the advisory list for self-classification
- 2.1 The selected dangerous properties
- 2.2 The evaluated chemical substances
- 2.3 Test data
- 2.4 Reliability of (Q)SAR-predictions
- 2.5 Validation
- 2.6 Applicability domain
- 2.7 Application of the models
- 2.8 The result
- 2.9 How the self-classification list can help manufacturers and importers to comply with the classification duties
Following development of new and/or improved (Q)SAR-models the list of advisory self-classification of dangerous substances has been updated. This chapter of the report presents the methodology applied for this new version of the advisory list for self-classification of dangerous substances.
2.1 The selected dangerous properties
The following endpoints were addressed using (Q)SARs :
- Mutagenicity
- Carcinogenicity
- Reproductive toxicity (possible harm to the unborn child)
- Hazard to the aquatic environment
Two endpoints have not yet been updated in AL2009:
- Acute oral toxicity
- Sensitization by skin contact
(Q)SAR-predictions for these endpoints were used to assign the classifications listed in Table 1.
| Dangerous property | Classification | Wording of Classification |
| Mutagenicity | Mut3;R68 | Mutagen, category 3; possible risk of irreversible effects |
| Carcinogenicity | Carc3;R40 | Carcinogen, category 3; possible risk of irreversible effects |
| Reproductive toxicity | Repr3; R63 | Reproductive toxicant, category 3, Possible risk of harm to the unborn child |
| Danger to the aquatic environment | N;R50 | Dangerous for the environment; very toxic to aquatic organisms |
| N;R50-53 | Dangerous for the environment; very toxic to aquatic organisms, may cause long-terms adverse effects in the aquatic environment | |
| N;R51-53 | Dangerous for the environment; toxic to aquatic organisms, may cause long-terms adverse effects in the aquatic environment | |
| N; R52-53 | Harmful to aquatic organisms, may cause long-terms adverse effects in the aquatic environment |
Table 1: Advisory classifications in AL2009
2.2 The evaluated chemical substances
The overall purpose of the current project was to evaluate as many chemical substances as possible with relevance to the existing regulation for chemicals within the EU.
Under REACH /1/ all chemicals with tonnages above 1 ton/year were pre-registered between June 1st 2008 and December 1st 2008. It would have been relevant to evaluate all chemicals in this inventory but at the time of preparation of AL2009 no official list existed.
It was therefore decided to base this project on the EINECS list /3,4/. This list consists of 100,204 entries, covering organic and inorganic substances in both single substance entries (mono-constituent substances) and mixtures (multi-constituent substances and UVBCs).
The exercise was limited to cover "discrete organics," meaning that multi-constituent substances and UVCBs (Unknown, Variable Composition and Biologicals) were excluded for practical reasons – “if you don’t know what it is, you can’t model it”.
Inorganic substances have likewise not been evaluated. These are usually better approached by simpler methods of evaluating the availability of the respective an- and cations with well-known hazard profiles. "Organo-metallics" have also been excluded as being poor candidates for modelling. As an error check, only such structural representations, which could be successfully converted to 3D were used /10/.
When it was possible using a CAS number comparison, all substances already classified on the list with formal EU harmonized classifications, Annex I of Directive 67/548/EEC (List of dangerous substances, /2/) were also removed. However, as there is no official overview of the substances covered by the group entries in Annex I, and because a chemical may have more than one CAS number, a few chemicals covered by Annex I may not have been removed from AL2009.
This resulted in a total of 49,292 discrete organic substances, or about half of all EINECS chemicals, which could be subjected to (Q)SAR based assessment.
2.3 Test data
For the vast majority of the assessed chemicals no test data were available. However, if test data were available as part of the (Q)SAR-model, this was generally used in preference to the estimates.
It is important to stress that no attempt was made to search published or unpublished databases for toxicological, ecotoxicological or environmental fate information to determine whether a (Q)SAR was necessary for any endpoint assesssed.
2.4 Reliability of (Q)SAR-predictions
The reliability of (Q)SAR-predictions depend on numerous parameters relating to the mathematical methods used, the number and precision of the underlying data used for developing the model and how suitable the model is for the particular substance.
In general the uncertainty of (Q)SARs is caused predominantly by two different reasons: a) the inherent variability of the input data used to establish the model (training set); and b) the uncertainty resulting from the fact that a model can only be a partial representation of reality (in other words does not model all possible mechanisms concerning a given endpoint and does not cover all types of chemicals). However, as a model averages the uncertainty over al chemicals, it is possible for an individual model estimate to be more accurate than an individual measurement /9/.
The reliability of (Q)SAR predictions can be described in many ways. Usually a range of parameters and concepts are used (see e.g. /9/ for a more extensive review). These concepts may not be known by all readers. Annex 1 contains descriptions of the concepts applied in this report.
2.5 Validation
Validation is a trial of the model performance for a set of substances independent of the training set, but within the domain of the model. The model predictions for these substances are compared with measured endpoints for the substances in order to establish the predictivity of the model.
Ideally all models should be assessed by checking how well they predict the activity of chemicals, which were not used to make them. This is, however, not always simple. In part valuable information may be left out by setting aside chemicals to be used in such an evaluation, and in part it can be extremely difficult to assess how “external” chemicals relate to the model’s domain; that is, if they represent a random distribution within this domain and thereby giving a fair picture of the predictivity of the model.
This problem is often addressed by using one or another form of cross-validation, where a number of partial models are “externally validated” by splitting the training set into a reduced training set and a testing set. The reduced training set is used to develop a partial model, while the remaining data are used as a test set to evaluate the model predictivity.
This is repeated a number of times and the results are used to calculate the predictivity measures for the models; for quantitative models in the form of Q² and SDEP (standard deviation error of prediction), and for qualitative (yes/no) models in the form of sensitivity, specificity and concordance (se Annex 1 and refs /9/ and /11/ for further details).
While drawbacks of cross-validation exist /14, 15/, much of the criticism is directed towards a particular form of cross validation; the leave-one-out cross-validation /14/. In the validations carried out on the models applied in this project the more stable leave-many-out cross-validation approach by leaving out random pos/neg balanced sets of 50% of the chemicals, repeated ten times, was used /13/. Leaving out 50% of the chemicals in the partial validation models is a large perturbation of the training set, which generally leads to realistic, and often pessimistic, measures of the predictivity of the model.
The commercial cancer models were validated by external validation /24/.
Concordance will vary depending on both the method used, and the endpoint in question. In general, accuracy of contemporary (Q)SAR systems can often correctly predict the activity of about 70 – 85% of the chemicals examined, provided that the query structures are within the domains of the models. This also applies to the models described in this paper.
QSAR Model Reporting Formats (QMRF’s) for all the toxicity models applied in this project, including training sets for the DK models, have been submitted to the EU JRC QSAR Model Database and the OECD QSAR Application Toolbox /35, 37/.
2.6 Applicability domain
When applying (Q)SAR’s it is important to assure that an obtained prediction falls within the domain of the models i.e., that there is sufficient similarity (in relevant descriptors) between the query substance and substances in the training set of the model.
There is no single and absolute applicability domain for a given model /9/. Generally, the broader the applicability domain is defined the lower predictivity can be expected. The applicability domain should be clearly defined and the validation results should correspond to this defined domain, which is again used when the model is applied for predictions.
The applicability domains for MultiCASE models as defined by the US Food and Drug Administration (FDA) and implemented in the MultiCASE software were used in this project: No warnings in the predictions were accepted, except warning for one unknown fragment in chemicals where a significant biophore has been detected. Only positive predictions where no significant deactivating fragments were detected were accepted.
For aquatic toxicity endpoints, warning for one unknown fragment in chemicals which were predicted negative was also accepted, as these chemicals underwent prediction by a subsequent model (a log Kow equation) to predict if they exerted aquatic toxicity by non-polar narcosis.
The EPISUITE models for rapid biodegradation /43, 45/ and the bioconcentration factor in fish /42/ do not automatically flag the predictions for domain coverage. No attempts have been made to consider the applicability domain for predictions made by these models.
Depending on the endpoint in question, predictions outside the applicability domain were obtained for between 27 and 58% of the chemicals examined by the individual MultiCASE models.
2.7 Application of the models
It is important to note that the applied models in principle do not predict a "classification" – they predict a biological activity that may lead to a classification.
Because of the large number of chemicals involved, “rules” were used for each endpoint to try and link the biological prediction with a risk phrase. In essence the process is no different than that imposed upon a human expert forced to interpret the information available in order to comply with the duty to make an assessment and self-classification.
The applied models have been used in combinations / batteries within the chosen classification endpoints to reach a final call in an attempt to reach further reliability beyond individual model predictions and to best comply with the classification criteria.
2.8 The result
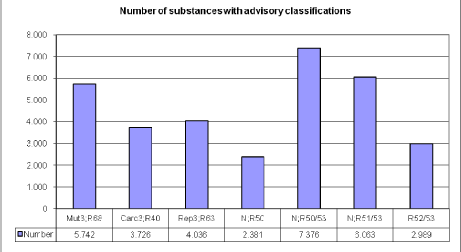
The result of the computer-based assessment is AL2009 which comprises 23,922 chemical substances with advisory classifications for one or more of the dangerous properties selected.
The results only represent POSITIVE predictions (for quantitative models “positive” here means predicted to have the effect or property as determined in relation to a cut-off point). No distinction has been made between a negative prediction for an endpoint, and an unreliable prediction (prediction outside the applicability domain of the model), which was simply discarded.
Evaluated substances which are not on the list, or substances which are on the list but without advisory classifications for one or more of the selected dangerous properties, may have been predicted as not having this / these dangerous properties, or the models may not have been valid for this substance (i.e. predictions were outside the applicability domain for these models).
Therefore the advisory list cannot be used to conclude that these substances do not possess dangerous properties.
Another important point is that AL2009 represent (Q)SAR based identifications of possible hazardous properties of the included chemicals; no attempt has been made to evaluate the risk that these chemicals constitute in their current use in the EU.
All results are available on the website of the Danish EPA (www.mst.dk) where searches can be made on substance name (in Danish), CAS-number, EINECS-number, EINECS-name, CAS-name and chemical formula. The whole list can also be downloaded as an Excel file.
2.9 How the self-classification list can help manufacturers and importers to comply with the classification duties
By making the advisory list for self-classification of dangerous substances available to the public, the Danish EPA wishes to offer manufacturers and importers a tool which can be used when carrying out self-classification of chemical substances for those dangerous properties which are included in the list.
If available, reliable test data or predictions using other non-test methods on specific substances should always be considered in parallel to computer predictions and expert judgements in a weight of evidence (WoE) approach to decide on the appropriate classification for a given endpoint.
It is recommended that the list is used in the following way in the classifications of chemicals:
- Examine if the substance is on Annex VI, table 2 of the EU regulation for classification, labelling and packaging of dangerous substances /6/. If so it should be classified accordingly. For non-classified endpoints no classification can be recommended, unless new information becomes available.
- If the substance is not in Annex VI, table 2, it should be classified according to the criteria in the Regulation for classification, packaging and labelling of dangerous substances /6/ using all available test and non-test data, including AL2009.
[1] 1. Roberts G., Myatt G.J., Johnson W.P., Cross K.P., Blower P.E., ”LeadScope: Software for Exploring Large Sets of Screening Data”, J. Chem. Inf. Comput. Sci., 2000, 40 (6), 1302-1314.
[2] J. Matthews and J.F. Contrera. A new highly specific method for predicting the carcinogenic potential of pharmaceuticals in rodent using enhanced MCASE (Q)SAR-ES software. Reg. Toxicol. and Pharmacol. 28 (1998) pp. 242-264.
[3] Positive according to the FDA ICSAS methodology corresponds to two or more positive cancer calls, accepting only predictions for chemicals without significant deactivating fragments. See footnote 2 for reference.
[4] The criteria for the overall call for genotoxicity is the one used for advisory classifications and described in 3.1 Mutagenicity; positive experimental test result in at least one training set or positive predictions in at least two models.
Version 1.0 September 2009, © Danish Environmental Protection Agency