The Advisory list for self-classification of dangerous substances
3 Technical description of the self-classifications
- 3.1 Mutagenicity
- 3.2 Carcinogenicity
- 3.3 Reproductive toxicity
- 3.4 Danger to the aquatic environment
The current chapter gives the detailed description of how the advisory classifications were assigned to the chemicals in the advisory list for self-classification. This includes description of the classification rules and the (Q)SARs used for predicting the dangerous properties of the chemicals. It must be noted that the advisory classifications for acute oral toxicity and sensitisation by skin contact have not been updated. The advisory classifications for these two endpoints are still recommended for use with the documentation as given in the previous version of self-classification list /5/.
3.1 Mutagenicity
The criteria for classification for mutagenicity are divided into 3 different categories:
Classification as mutagen, category 1 (Mut1;R46, May cause heritable genetic damage) is based on evidence of a causal association between human exposure to the substance and heritable genetic damage.
Classification as mutagen, category 2 (Mut2;R46, May cause heritable genetic damage) is based on animal studies showing mutagenity to germ cells either in assays on germ cells or by demonstrating mutagenic effects in somatic cells in vivo or in vitro as well as metabolic proof that the substances reaches the germ cells.
The criteria for classification as mutagen, category 3 (Mut3;R68, Possible risks of irreversible effects) is based either on in vivo mutagenicity tests or on cellular interactions with in vitro tests acting as supportive evidence. For this classification, it is not necessary to demonstrate germ cell mutations.
(Q)SAR based evaluation
Five models predicting genotoxicity in vivo endpoints were applied in the screening. Data for the training sets were obtained from the literature. The technical specifications for the models are given in Table 2.
Drosophila melanogaster Sex-Linked Recessive Lethal (SLRL) (in vivo)
The training set consists of data from Lee et al. /16/. In the experimental method, Drosophila melanogaster males and females are used. Males are treated with the test substance and mated individually to virgin females. The test detects the occurrence of mutations, point mutations and small deletions, in the germ line of the insect. The mutations are phenotypically expressed in males carrying the mutant gene. When the mutation is lethal in the hemizygous condition, its presence is inferred from the absence of one class of male offspring out of the two that are normally produced by a heterozygous female. The assay has a low sensitivity for genotoxins other than direct-acting agents and simple promutagens, but a very high specificity, which means that in general a positive result has considerable value for prediction of potential genotoxicity in mammals.
Mutations in mouse micronucleus (in vivo)
The training set includes data from Hayashi et al. /17/, Mavournin et al. /18/, Waters et al. /19/, and Morita et al. /20/. The test detects micronuclei produced by damage to the chromosomes or the mitotic apparatus in red blood cells. Micronuclei are small nuclei produced during cell division. They contain chromosome fragments or whole chromosomes. In the test, mice are exposed to the test substance and young red blood cells (erythrocytes) from the bone marrow are isolated and analysed for micronucleus. The test is especially relevant to assess mutagenic hazard in that it allows consideration of factors of in vivo metabolism, pharmacokinetics and DNA-repair processes.
Dominant lethal effect in rodents (in vivo)
The training set is comprised of data from Green et al. /21/ and other references. In the experimental method, mice and rats are used. Treated males are mated to virgin females according to an experimental scheme. Females are sacrificed in the second half of pregnancy and uterine contents are examined to determine the number of implants and live and dead embryos. The category of early embryonic deaths is the most significant index of dominant lethality and as such used as endpoint. The test identifies major genetic damage, mainly the induction of structural and numerical chromosomal anomalies.
Sister chromatid exchange in mouse bone marrow (in vivo)
Data from Tucker et al. /22/ are used in the training set. The sister chromatid exchange (SCE) assay detects interchange of DNA between two sister chromatids of a duplicating chromosome. Mice are exposed to the test chemical. Then a thymidine analog, bromodeoxyuridine (BrdU) is injected. If DNA exchanges occur, BrdU can be identified by use of a fluorescence technique in chromosomes in the metaphase. The test is considered to be a sensitive method for evaluating mutagenicity and may be an indicator of carcinogenicity.
Comet assay in mouse (in vivo)
The training set includes data from Sasaki et al. /23/ plus a number of physiological chemicals theoretically assumed not to have the effect (such as various amino acids, sugar molecules, fatty acids etc.). The latter was included to get a better distribution between positives and negatives in the training set for the model). Included in the training set of the model are results from eight tissue types; stomach, colon, liver, kidney, bladder, lung, brain and bone marrow. The comet assay detects DNA strand break and can be applied to virtually any organ of interest. In the experimental test, a microgel electrophoretic technique is used for detecting DNA damage at cell level. The tested chemical is positive if it produces breaks in DNA-strings, resulting in small strings of DNA that are able to migrate further in a microgel, than intact DNA strings. In the microscope, damaged DNA is seen as a “comet” while not damaged DNA appear as a dot. If appropriately performed, the test has been shown to be reliable with high sensitivity to detect DNA damage in organs that cannot be investigated in other classical mutagenicity assays.
| Model | Technical summary |
| Drosophila melanogaster Sex-Linked Recessive Lethal (in vivo) | MultiCASE, DK model Training set: n=377 Cross-validation 10*50% gave Sensitivity: 73.9% Specificity: 88.0% Concordance: 81.6% Domain: 48% |
| Mutations in mouse micronucleus (in vivo) | MultiCASE, DK model Training set: n=358 Cross-validation 10*50% gave Sensitivity: 30.1% Specificity: 84.5% Concordance: 66.1% Domain: 59% |
| Dominant lethal mutations in rodent (in vivo) | MultiCASE, DK model Training set: n=191 Cross-validation 10*50% gave Sensitivity: 41.3% Specificity: 95.2% Concordance: 75.9% Domain: 42 |
| Sister chromatid exchange in mouse bone marrow (in vivo) | MultiCASE, DK model Training set: n=265 Cross-validation 10*50% gave Sensitivity: 70.4% Specificity: 86.9% Concordance: 85.5% Domain: 53% |
| COMET assay in mouse (in vivo) | MultiCASE, DK model Training set: n=286 Cross-validation 10*50% gave Sensitivity: 63.3% Specificity: 93.3% Concordance: 83.9% Domain: 45% |
Table 2: Technical summary for the mutagenicity models

Figure 1: Schematic diagram illustrating the systematic evaluation applied to assign advisory classifications for mutagenicity.
For a substance to be selected as a probable mutagen it was necessary for the following criteria to be fulfilled: Positive prediction in two or more models, accepting only predictions where no significant deactivating fragments were detected. If one or more positive tests could be seen (as part of the training sets for the models) for any genotoxicity endpoint, this took precedence over model predictions.
When classification is proposed on basis of test data, a positive result in a single in vivo test is sufficient evidence on which to base the classification. In contrary to that, positive predictions in at least two models were required here.
5,742 of the chemicals investigated in the current project met the criteria in the systematic evaluation and were assigned advisory classifications Mut3;R68.
3.2 Carcinogenicity
This endpoint can result in classification in 3 different categories:
Classification as carcinogen in category 1 (Carc1;R45, Toxic; May cause cancer, or Carc1;R49, Toxic; May cause cancer by inhalation) is based on a strong causal relationship in humans.
Classification as carcinogen in category 2 (Carc2;R45, Toxic; may cause cancer, or Carc2;R49, Toxic; may cause cancer by inhalation) is based on conclusive animal data from 2 species or 1 species with supportive evidence such as genotoxic effects in vitro or in vivo.
Classification as carcinogen in category 3 (Carc3;R40, Harmful; Possible risks of irreversible effects”) is subdivided into two:
- Well-investigated substances with restricted tumorigenic effects. It is normally based on clear data of tumour formation in one species. Mutagenicity data in vitro and in vivo can be used as supportive evidence.
- Substances that are insufficiently investigated, but raising concern for man.
(Q)SAR based evaluation
Four models predicting carcinogenicity in vivo and models predicting three genotoxicity in vitro endpoints were applied in the screening. Commercial MultiCASE training sets constitutes the basis of the carcinogenicity models. The technical specifications for the models are given in Table 3.
Carcinogenicity male and female, rats and mice (in vivo)
The models are the MultiCASE commercial models AG1-4 /24/. The training sets were constructed using the NTP (US National Toxicology Program) rodent carcinogenicity database, the Lois Gold Carcinogen Potency Database, FDA/CDER (US Food and Drug Administration / Center for Drug Evaluation and Research) archives, and the scientific literature. Training sets include both non-proprietary and proprietary data. Proprietary (confidential) data constitute around ten percent of the training sets. The open models based on the non-proprietary data were also available and consulted in the screening process.
In the experimental test, the test substance is administered by an appropriate route to the animals for a major portion of their lifespan. The highest dose level should elicit signs of toxicity, without substantially altering the normal lifespan due to effects other than tumours. During and after exposure, the animals are observed daily to detect signs of toxicity, particularly the development of tumours.
Reverse mutation test, Ames (in vitro)
The training set is from Kazius et al. /25/. The bacterial reverse mutation test detects point mutations, which involve substitution, addition or deletion of one or a few DNA base pairs. Amino-acid (histidin) requirering strains of Salmonella typhimurium are used. Mutations, which revert mutations present in the test strains and restore the functional capability of the bacteria to synthesise the amino acid (histidin), are detected. These appear by the ability of the bacteria to grow in the absence of histidin required by the parent test strain. The test is a useful tool as an initial screen for potential in vivo genotoxic activity, and has become the most extensively used in vitro short-term test in the screening for mutagenicity.
Chromosomal aberration CHO/CHL (in vitro)
This model was used by Niemela and Wedebye /28/ to evaluate the OECD principles for development and validation of (Q)SARS /27/. The Chinese Hamster Ovary (CHO) model is the commercial MultiCASE model A61 /26/ and the training set for the Chinese Hamster Lung (CHL) model was taken from Ishidata /28,29/. The in vitro mammalian chromosome aberration test identifies agents that cause structural chromosome aberrations in cultured cells. Chromosome damage is expressed as breakage of single or both chromatids, sometimes followed by reunion between chromatids or of both chromatids at an identical site. Many compounds that are positive in this test are mammalian carcinogens causing DNA damage.
Mutations in mouse lymphoma (in vitro)
The training set is comprised of data from Grant et al. /30/. The mouse lymphoma assay detects mutations affecting the heterozygous thymidine kinase (TK) locus. It identifies chemicals acting as clastogens (delete, add, or rearrange chromosome sections) as well as point mutagens. Mutations in genes coding for TK are identified. TK is involved in the phosphorylation of thymidin and subsequently in the formation of DNA. Positive chemicals may give rise to mutations in genes coding for TK. A mutation may result in loss of the ability to phosphorylate the pyrimidin analogs, which is detected by the test. The assay has a reputation for high sensitivity and low specificity of detecting genotoxic agents. However, in this exercise the model is used to give mechanistic information to chemicals already predicted to be carcinogens.
| Model | Technical summary |
| Carcinogenicity in male rat (in vivo) | MultiCASE, AG1 Training set: n=1381 External validation (100 chemicals): Sensitivity: 58.6% Specificity: 97.6% Concordance: 75.0% Domain: 70% |
| Carcinogenicity in female rat (in vivo) | MultiCASE, AG2 Training set: n=1376 External validation (100 chemicals): Sensitivity: 58.6% Specificity: 97.6% Concordance: 75.0% Domain: 70% |
| Carcinogenicity in male mouse (in vivo) | MultiCASE, AG3 Training set: n=1252 External validation (100 chemicals): Sensitivity: 58.6% Specificity: 97.6% Concordance: 75.0% Domain: 71% |
| Carcinogenicity in female mouse (in vivo) | MultiCASE, AG4 Training set: n=1263 External validation (100 chemicals): Sensitivity: 58.6% Specificity: 97.6% Concordance: 75.0% Domain: 71% |
| Reverse mutation test, Ames (in vitro) | MultiCASE, DK model Training set: n=4102 Cross-validation 10*50% gave Sensitivity: 84.4% Specificity: 82.5% Concordance: 83.5% Domain: 73% |
| Chromosomal aberration CHO (in vitro) | MultiCASE, A61 Training set: n=233 Cross-validation 10*50% gave Sensitivity: 32.0% Specificity: 91.2% Concordance: 69.9% Domain: 45% |
| Chromosomal aberration CHL (in vitro) | MultiCASE, DK model Training set: n=600 Cross-validation 10*50% gave Sensitivity: 57.8% Specificity: 86.5% Concordance: 74.3% Domain: 64% |
| Mutations in mouse lymphoma (in vitro) | MultiCASE, DK model Training set: n=555 Cross-validation 10*50% gave Sensitivity: 68.5% Specificity: 86.3% Concordance: 79.2% Domain: 64% |
Table 3: Technical summary for the carcinogenicity models
Identification of carcinogenic substances
For a substance to be selected as a probable carcinogen it was necessary for the following criteria to be fulfilled: Positive according to the ICSAS methodology /24/, corresponding to two or more positive carcinogenicity predictions, accepting only predictions for chemicals without significant deactivating fragments. If one or more positive tests could was observed (as part of the training sets for the models) for any cancer endpoint, this took precedence over model predictions.
While in most cases this resulted in little change (the models are heavily biased towards making a correct prediction for substances used to make them), it was felt that there was no reason to artificially reduce the quality of the advisory classification by neglecting to use data, which happen to be present. One or more negative tests in the training set of each model also took precedence over predictions of that model, except in cases where positive training set tests were present in other cancer models.
Employing this carcinogenicity identification algorithm resulted in a list of 3,726 positive predictions.

Figure 2: Schematic diagram illustrating the systematic evaluation applied to assign advisory classifications for carcinogenicity.
Identification of genotoxic carcinogens
While there are many non-genotoxic carcinogens acting by a wide variety of often-unknown mechanisms, it was chosen to focus here on chemicals likely to cause cancer through a genotoxic mechanism. Therefore, a further selection criterion for genotoxicity was set up.
As opposed to the selection criteria for mutagenicity, not all genotoxic carcinogens are necessarily clastogenic (cause loss, addition or rearrangement of parts of chromosomes). To select the genotoxic chemicals from the chemicals already predicted positive for in vivo carcinogenicity,which include genotoxic as well as non-genotoxic carcinogens, a battery of models for sensitive in vitro genotoxicity endpoints was used.
The genotoxicity criterion was a positive estimate in one or more of the models for the following in vitro genotoxicity endpoints; Reverse mutation test (Ames), chromosomal aberrations (CHO/CHL), or mutations in mouse lymphoma.
A schematic diagram of the systematic evaluation is given in Figure 2. According to these criteria, 3,726 of the chemicals assessed in the current project were identified as genotoxic carcinogens and selected for advisory classification for carcinogenicity. It is not felt that the models employed allow discrimination between classification in the three categories, so the lower classification Carc3;R40 was applied in all cases.
3.3 Reproductive toxicity
This endpoint can result in classification in 3 different categories:
Classification as toxic to reproduction in category 1 (Rep1;R60, Toxic; May impair fertility, or Rep1;R61, Toxic; May cause harm to the unborn child) is based on a strong causal relationship in humans.
Classification as toxic to reproduction in category 2 (Rep2;R60, Toxic; May impair fertility, or Rep2;R61, Toxic; May cause harm to the unborn child) is based primarily on animal data, and secondly on “other relevant information”. Data from in vitro studies, or studies on avian eggs, are regarded as “supportive evidence” and would only exceptionally lead to classification in the absence of in vivo data.
Classification as toxic to reproduction in category 3 (Rep3;R62, Harmful; Possible risks of impaired fertility, or Rep3;R63, Harmful; Possible risk of harm to the unborn child) is based primarily on animal data, and secondly on “other relevant information”. Substances in category three are insufficiently investigated, but raising concern for man.
Classification for reproductive toxicity covers a wide range of effects on either fertility or to the developing organism before and after birth (structural or functional damage). The (Q)SAR models applied in the current project only cover certain but far from all types of harm to the unborn child. Hence only certain types of mechanisms causing malformations or death are covered. Furthermore, no (Q)SAR models were used for effects on fertility.
(Q)SAR based evaluation
Three models predicting in vivo teratogenicity or fetal lethality related endpoints were applied in the assessment. A commercial MultiCASE training set constitutes the basis of one model. Data for the training sets for the two other models were obtained from the literature. The technical specifications for the models are given in Table 4.
Teratogenic risk (in vivo)
The model is the MultiCASE commercial model A49 /31/. The training set is composed of data taken from the TERIS (Teratogen Information System) and a compilation in which the FDA (US Food and Drug Administration) definitions were used to quantify risk of developmental toxicity from drugs used during pregnancy. The training set consists of clinical and epidemiologicdata. Many biological mechanisms are involved in the effects.
Drosophila melanogaster SLRL effect (in vivo)
The training set consists of data from Lee et al. (1983) /32/. In the experimental method, Drosophila melanogaster males and females are used. Males are treated with the test substance and mated individually to virgin females. The test detects the occurrence of mutations, point mutations and small deletions, in the germ line of the insect. The mutations are phenotypically expressed in males carrying the mutant gene. When the mutation is lethal in the hemizygous condition, its presence is inferred from the absence of one class of male offspring out of the two that are normally produced by a heterozygous female. The assay has a low sensitivity for genotoxins other than direct-acting agents and simple promutagens, but a very high specificity.
Dominant lethal effect in rodents (in vivo)
The training set is comprised of data from Green et al. (1985) /33/ and other references /21/. In the experimental method, mice and rats are used. Treated males are mated to virgin females according to an experimental scheme. Females are sacrificed in the second half of pregnancy and uterine contents are examined to determine the number of implants and live and dead embryos. The category of early embryonic deaths is the most significant index of dominant lethality and as such used as endpoint. The test identifies major genetic damage, mainly the induction of structural and numerical chromosomal anomalies.
| Model | Technical summary |
| Teratogenic risk in humans (in vivo) | MultiCASE, A49 Training set: n=323 Cross-validation 10*50% gave Sensitivity: 50.2% Specificity: 91.3% Concordance: 79.3% Domain: 48% |
| Mutations in Drosophila melanogaster SLRL (in vivo) | MultiCASE, DK model Training set: n=377 Cross-validation 10*50% gave Sensitivity: 73.9% Specificity: 88.0% Concordance: 81.6% Domain: 48% |
| Dominant lethal mutations in rodent (in vivo) | MultiCASE, DK model Training set: n=191 Cross-validation 10*50% gave Sensitivity: 41.3% Specificity: 95.2% Concordance: 75.9% Domain: 42% |
Table 4: Technical summary for the models for reproductive toxicity.
The dominant lethal test in rodents and the Drosophila SLRL test are initially meant for genotoxicity effects on germ cells, but the resulting effect is early embryonic deaths and lethal effect on offspring, respectively. Therefore, the endpoints are relevant for reproductive toxicity assessment.
In many cases, a toxicological threshold is assumed to exist for reproductive toxicity. With mutagenic chemicals this may not be the case.

Figure 3: Schematic diagram illustrating the systematic evaluation applied to assign advisory classifications for reproductive toxicity.
For a substance to be selected as probable toxic to reproduction in the assessment, the criterion was a positive prediction in any of the three models and without a negative prediction in the teratogenic risk in humans model (see Figure 3) (see also /34/).
The screening resulted in a list of 4,036 positive predictions. The models employed do not allow discrimination between classification in the three classification categories, so the lower classification Rep3;R63 was applied in all cases.
3.4 Danger to the aquatic environment
The classification criteria are composed of three main elements: 1) potential for rapid degradation, 2) bioconcentration potential in fish, and 3) short-term toxicity to aquatic organisms (fish, daphnia, and algae). Classifications are assigned according to the following scheme:
| Classification | Classification criteria* |
| N;R50 Dangerous for the environment; very toxic to aquatic organisms |
Acute toxicity ≤ 1.0 mg/L |
| N;R50/53 Dangerous for the environment; very toxic to aquatic organisms; may cause long-term adverse effects in the aquatic environment |
Acute toxicity ≤ 1.0 mg/L and not readily degradable or BCF** ≥ 100 |
| N;R51/53 Dangerous for the environment; toxic to aquatic organisms; may cause long-term adverse effects in the aquatic environment |
Acute toxicity > 1 and ≤ 10 mg/L and not readily degradable or BCF** ≥ 100 |
| R52/53 Harmful to aquatic organisms; may cause long-term adverse effects in the aquatic environment |
Acute toxicity > 10 and ≤ 100 mg/L and not readily degradable |
| R53 Harmful to aquatic organisms |
Solubility in water < 1 mg/L and not readily degradable and BCF** ≥ 100 |
Table 5: EU criteria for classification for danger to the aquatic environment
* The lowest effect concentration, EC50, for fish, daphnia or algae is used
** BCF: Bioconcentration factor
(Q)SAR based evaluation
Advisory classifications were assigned on the basis of combinations of estimates for ready biodegradability, bioconcentration and acute toxicity according to the criteria in Table 5. Classification with risk phrase R53 alone was not done in this exercise, as the strong co-linearity between water solubility and bioconcentration factor made it redundant.
It is noted that compared to the classification criteria according to which abiotic degradation (and assessment of primary degradation products for their environmental hazard classification) can be used, only predictions concerning potential for rapid biodegradation was employed here. Furthermore only predictions for bioconcentration in fish were used even though the classification criteria refers to use of log Kow when reliable measured BCF data in fish are not available.
Biodegradation
Biodegradability was estimated using the Syracuse BIOWIN program /43/. Only the non-linear equation for rapid/non-rapid biodegradation (BPP2) was applied. Previous validation of this parameter compared with 304 MITI “ready/not-ready (45:259) results showed that while a relatively high percentage of “not-ready” chemicals were missed (sensitivity result was 53%), 97% of “not ready” predictions were correct (PPV, Positive Predictive Value) in this “chemical universe” of 85% not-ready chemicals /44/. MITI data was also applied by Tunkel et al /41/ who found a sensitivity of 53%, a specificity of 86% and a PPV of 83% for 884 chemicals (385 ready: 499 not-ready). These findings were largely confirmed in a comparison exercise made by the Danish EPA and based on chemicals assessed at OECD (SIAM 11-18), where 128 chemicals (59 ready:69 not-ready), which were not part of the BPP2 training set indicated a sensitivity of 54%, a specificity of 85% and a positive predictive value of 80% /38/. In other words while this model may fail to identify around half of all “non-ready” substances, the number of false predictions for not-ready biodegradability will be very low.
A total of 11,766 chemicals of the 49,292 chemicals studied were found to be “not-readily degradable” according to this criterion.
Bioconcentration
The classification and labelling guidelines prefer measured data for bioconcentration, but as this rarely is available, a Log Kow of greater than three is recommended as an indication that BCF will be 100 or greater, in accordance with the linear equation of Veith /55/. While a good rule-of-thumb, this relation both over- and underestimates BCF for many classes of chemicals, and is only applicable in the Log Kow interval 2-6.
Bioconcentration was therefore predicted using Syracuse BCFWIN /42/, a method based on a combination of Log Kow relations and structural fragment categories. This method was evaluated by its authors as having a statistical accuracy of R² = 0.74 (n = 694, S.D. 0.65, mean error = 0.47), which is a significant improvement over the standard equation of Veith (log BCF = 0.85 * Log Kow – 0.70) where predictions for the same 694 compounds had a statistical accuracy of R² = 0.32 (S.D. 1.62 and mean error = 1.12).
No attempt was made to further assess bioaccumulation potential.
For chemicals predicted to have aquatic toxicity concentrations below 10 mg/L and to be readily biodegradable, 4,662 chemicals were predicted to have BCF estimates of equal to or greater than 100.
Acute toxicity
For aquatic toxicity classifications, it is recommended to used L(E)C50-values for fish, daphnia and algae. Aquatic toxicity to fish, daphnia and algae were predicted using three models and a theoretical equation.
Fish
For acute aquatic toxicity to fish a DK MultiCASE model using 96h LD50 data on 569 chemicals from the Duluth Fathead minnow database was applied /48/. Cross-validation of this model gave a R² of 0.735. As there was insufficient test data for very lipofilic substances the MultiCASE model was only applied for chemical substances with Log Kow of 6 or less.
Daphnia
For acute aquatic toxicity to daphnia a DK MultiCASE model using 48h EC50 data on 641 chemicals from various sources was applied /49/. Cross-validation of this model gave a R² of 0.69. As there was insufficient test data for very lipofilic substances the MultiCASE model was only applied for chemical substances with Log Kow up to 7.
Algae
For acute aquatic toxicity to daphnia a DK MultiCASE model using EC50 data on 531 chemicals (396 tests made at the Danish Technical University for the Danish EPA, plus literature data from various sources) /50/ was applied. Cross-validation of this model gave a R² of 0.74.
A regression equation was used on top of MultiCASE predictions to adjust for Log Kow contribution to the toxicity:
Log EC50 (μM) = 0.593*Log EC50 (MC4PC prediction, μM) – 0.257*Log Kow + 1.076
N = 343, R2 = 0.743, S.E = 0.853
(Log Kow below –1 were set to –1, Log Kow above 7 and less or equal to 8 were set to 5, and Log Kow above 8 were set to 1)
As there was insufficient test data for very lipophilic substances the MultiCASE model was only applied for chemical substances with Log Kow of up to 8.
Non-polar narcosis predictions for highly lipophilic substances
Another relationship was used for chemicals with a Log Kow of greater than six. Here, all substances were assumed to act by non-polar narcosis, and toxicity at equilibrium was estimated according to a relation to the predicted bioconcentration factor in small fish:
LC50 (equilibrium) = 8.15 mmol /BCF
The choice of 8.15 mmol corresponds to the theoretical level inducing aquatic lethal effects represented by the non-polar narcosis fish (Q)SAR recommended in the REACH-guidance /51/. Non-polar narcosis Lethal Body Burden’s for fish are generally assumed to be within the range of about 2–8 mmol /53/.
While simple Log Kow relationships exist for predicting the non-polar narcotic toxicity for fish, daphnia and algae, these do not distinguish specific toxicity’s unique to any of the three taxa, and were not felt to offer any advantage over using the fish models alone, which also adequately predict non-polar narcosis. For all practical purposes, non-polar narcosis induces effects at the same concentration levels in all three taxa at these high Log Kow values.
Aquatic toxicity screening
Using the three Multicase models and the non-polar narcosis equation, 18,809 of the chemicals assessed in the current project had acute aquatic toxicity’s of ≤ 100 mg/L.
| Model | Technical summary |
| Biodegradation, Syracuse BIOWIN2 non-linear model for rapid/non-rapid aerobic biodegradation probability (BPP2) | Syracuse BIOWIN, US EPA /45/ Training set: n=295 External validation (n=304) gave Sensitivity: 53.3% Specificity: 91.1% Concordance: 58.9% PPV: 97.2% |
| Bioconcentration (BCF), Syracuse BCFWIN | Syracuse BCFWIN, US EPA /42,46/ Training set: n=694 Cross-validation gave R² = 0.74 S.D. = 0.65 Mean error = 0.47 |
| Acute toxicity to fish, Fathead minnow LC50 (96h) | MultiCASE, DK model /48/ Training set: n=569 Cross-validation 3*10% gave R² = 0.74 Domain: 52% |
| Acute toxicity to daphnia, Daphnia magna, EC50 (48h) | MultiCASE, DK model /49/ Training set: n=641 Cross-validation 3*10% gave R² = 0.69 Domain: 52% |
| Acute toxicity to algae, Pseudokirchneriella subcapitata, EC50 | MultiCASE, DK model /50/ plus Log Kow equation Training set: n=531 Cross-validation 10*50% for the two-step model gave R² = 0.74 Domain: 58% |
| Non-polar narcosis, LC50 (equilibrium) = 8.15 mmol /BCF | Theoretical equation /51-54/ |
Table 6: Technical summary for the models used for classification of danger to the aquatic environment.
Advisory classifications
A total of 18,809 of the chemicals assessed in the current project were selected according to one of the four classification categories based on the combination of model predictions as indicated in the classification criteria and shown in Figure 4. The classifications for danger to the aquatic environment were assigned to the following number of chemicals:
| N;R50 | 2,381 |
| N;R50/53 | 7,376 |
| N;R51/53 | 6,063 |
| N;R52/53 | 2,989 |
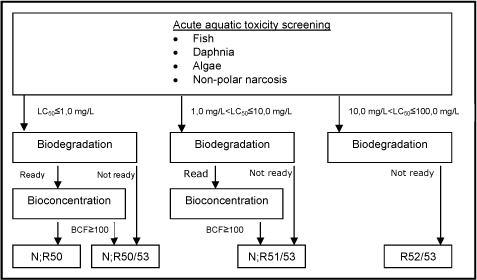
Figure 4: Schematic diagram illustrating the systematic evaluation applied to assign advisory classifications for danger to the aquatic environment.
Version 1.0 September 2009, © Danish Environmental Protection Agency