Fund af glyphosat og AMPA i drikkevand fra små vandforsyningsanlæg i Storstrøms Amt
Bilag 10
Statistisk bearbejdning af resultater fra Storstrøms Amt
- 1.1 Værktøjer
- 1.2 Principal komponent analyse og klassificering
- 1.3 Beskrivelse af principper for PCA, Cluster analyse og PLS-R
- 1.4 Statistisk bearbejdning af data fra 2001/2002 indsamlet i forbindelse med undersøgelse af små private vandforsyningsanlæg i Storstrøms Amt
- 1.5 Statistisk bearbejdning af data fra 2005 indsamlet i forbindelse med undersøgelse af anlæg med fund af glyphosat/AMPA i små private vandforsyningsanlæg i Storstrøms Amt
- 1.6 Konklusion for data indsamlet i 2005
Principal komponent analyse, Cluster analyser og partial least squares regression
1.1 Værktøjer
Den kemometriske undersøgelse er udført på standard PC med programmerne Matlab version 7.0 fra Mathworks inc., med tilføjelsesprogrammet PLS_Toolbox fra Eigenvector Research inc.
1.2 Principal komponent analyse og klassificering
De forskellige data sæt er blevet underkastet en såkaldt Principal Component Analysis (PCA), med henblik på dels at studere sammenhænge mellem variable (data), og dels med henblik på at undersøge hvorvidt boringer med fund af glyphosat og AMPA adskiller sig systematisk, og på hvilken måde, fra boringer uden fund. Den anvendte metode falder indenfor disciplinen kemometri. Kemometrien er vel etableret og vel beskrevet, men især tre kilder har været anvendt i det følgende:
- Brereton, 1992, Multivariate pattern recognition in chemometrics, illustrated by case stories
- Esbensen, K.H. 2002, Multivariate data analysis - in practice. 5th. edition. CAMO Process AS, Oslo, Norway.
- Wise Barry M. And Galagher Neal B., 1998, PLS toolbox tutorial.
I det følgende bliver der brugt betegnelserne variable om de data der er opnået på prøverne og objekter om prøverne.
1.3 Beskrivelse af principper for PCA, Cluster analyse og PLS-R
Principal Component Analyse (PCA)
PCA bruger princippet om at finde kombinationer af variable (faktorer eller såkaldte latente variable) til at beskrive tendenserne i datasættet. Normalt er variable ikke uafhængige og målet er med så få såkaldt latente variable at beskrive den systematiske variation i datasættet. Det svarer lidt til at man i et bivariat datasæt forsøger at lave lineær regression. Ved at gøre dette reducerer man antallet af variable fra to til en. Denne ene variabel er således en latent variabel, der ikke i sig selv kan oversættes til en bestemt egenskab, idet den er en linear kombination af de to variable. Den algoritme man anvender(mindste kvadraters metoder), sikrer at der er mindst mulig fejl på forudsigelserne lavet på modellen (regressionslinien).
I et multivariat tilfælde er det lidt mere kompliceret. Først finder man den retning i variabelrummet, det vil sige det rum hvori objekterne (prøverne) afbildes, der forklarer størst mulig af datasættets variation. Hernæst fortsætter man med en ny retning, idet det kræves at næste retning er orthogonal (det vil sige vinkelret) på den første, samtidigt med at man tilstræber at mest muligt variation i den resterende matrice forklares. Denne forudsætning sikrer at de latente variable, i modsætning til de reelle variable, er uafhængige. Korrelationen mellem to ortogonale vektorer er nul. Man har en række metoder til at vurdere antallet af latente variable der skal ekstraheres, dels kan man bruge sin sunde fornuft og vurdere residualet eller fejlen i forhold til målesikkerhed, og dels kan man se på modellens evne til at prediktere hver enkelt objekt for hver iteration i forhold til den foregående. Falder modellen prediktive evne, har man taget for mange latente variable med og man stopper med at ekstrahere flere komponenter.
Matematisk kan problemstillingen udtrykkes på følgende måde:
X = t1pT1 + t2pT2 + t3pT3 +……...+ t´npTn + E (1)
X er den originale datamatrice. Vektorerne tn er såkaldte loading vektorer der indeholder information om hvordan variablene relaterer sig til hinanden. Vektorerne pn er såkaldte score vektorer, svarende til de latente variable der er omtalt ovenfor. T angiver at vektoren er transponeret hvilket betyder at der byttes om på rækker og søjler. Når en vektor transponeres ændres den fra en søjle vektor til en række vektor. Som det fremgår af ovenstående er matricen X opløst i en linear kombination af matricer der er opnået ved at multiplicere loading vektorer og transponerede score vektorer. Man kan således repræsentere variablene i den originale matrice i et rum udspændt af loading vektorerne eller objekterne i den originale matrice i et rum udspændt af score vektorerne. Matricen E angiver residual matricen, eller fejlen på modellen i forhold til det originale data sæt (X).
Loading vektorerne udregnes ud fra covarians matricen på X:
Cov(X)=XTX/(m-1) (2)
Hvor m er lig med antallet af variable i datasættet. Loading vektor, for i’te iteration, findes som eigenvektoren til covarians matricen på X idet:
Cov(X)pi = λipi (3)
Her er λi eigenværdien for den pågældende eigenvektor pi (loading vektoren for i’te iteration).
Den tilsvarende score vektor ti findes ud fra formlen:
Xpi = ti (4)
Score vektorerne er orthogonale, på samme måde som loading vektorerne der desuden er orthonormale (længden 1) og ti kan forstås som den originale matrices projektion på den tilhørende loadingvektor pi.
Da eigenværdierne har den egenskab, at den første er den største, og at de derefter falder i værdi, opfylder loadingvektorerne og dermed scorevektorerne den egenskab at de tilsammen indeholder en faldende mængde information om datamatricen, efterhånden som iterationen skrider frem. Oplever man at eigenværdier stiger mellem to iterationer, tyder dette ofte på at datasættet indeholder flere klasser, eller at man modellerer på støjen i data sættet, hvilket kan bruges aktivt. Der findes desuden en række valideringsprincipper så kun signifikante komponenter ekstraheres fra datasættet.
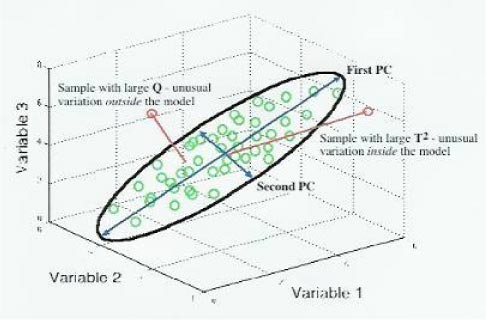
Figur 1 Illustration af PCA taget fra Wise and Gallagher.
Figur 1 viser princippet i PCA. Et tredimensionelt datasæt kan repræsenteres i to dimensioner ved hjælp af PCA analysen. Ellipsen illustrerer konfidensintervallet i planet udspændt af de to principal komponenter. Der vises to prøver der hver for sig illustrerer en outlier. Den ene prøve er karakteriseret ved at ligge i planet, men have en variation der er udenfor konfidensintervallet for tilfældig fejl (large T²). Dette svarer i tilfældet med lineær regression til at punktet ligger på regressionslinien men langt fra de punkter modellen er bygget over. Den anden prøve vil projiceret på planet ligge indenfor konfidensintervallet, men har en stor residual værdi (large Q). I tilfældet med lineær regression svarer det til et punkt der ligger langt fra regressionslinien.
T² og Q kan anvendes til at undersøge om to populationer, defineret ved hver deres PCA analyse, er statistisk signifikant forskellige, idet T² og Q afstandskriteriet anvendes i en såkaldt SIMCA(Soft Independent Modelling of Class Analogies) analyse.
Grafiske fremstillinger
Der anvendes en række grafiske fremstillinger i forbindelse med den kemometriske behandling af data.
Figur 2 viser et såkaldt score plot, altså en projektion af objekterne på det reducerede variabel sæt. I dette tilfælde er der 5 signifikante principal komponenter (her vises dog kun de to), og man skal være opmærksom på at der er variationer i andre dimensioner end de der fremgår af det to dimensionale plot. Som det fremgår bærer første principale komponent godt 48% af variationen i data sættet og er altså den vigtigste, mens principal komponent 2 bærer godt 17%. Man kan i score plottet studere sammenhængen mellem objekterne, jo tættere de liggere, des mere lig er de. I dette som i alle andre plots der vil blive vist, er korrelationen mellem to objekter (eller variable senere), projektionen af den vektor der går fra (0,0) til det ene punkt på den vektor der går fra (0,0) til det andet punkt (i de viste dimensionen!). Er vinklen mellem de to vektorer nul, er objekterne eller variablene uafhængige. Tager man f.eks. nedenstående loading plot (figur 3), og vil estimere korrelationen mellem ilt (o2) og metan (ch4), trækker man en linie mellem punktet (0,0) og punktet o2 samt mellem (0,0) og punktet ch4. Korrelationen er da projektionen af den ene linie på den anden. Des tættere vinklen mellem linierne er på 90 grader, des lavere bliver korrelationen.
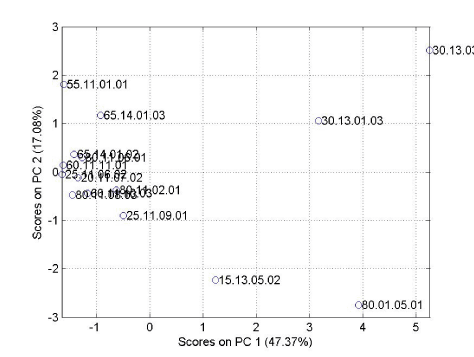
Figur 2 Score plot.
Loading plottet, figur 3, viser sammenhængen mellem variablene projiceret på de samme to principal komponenter som i figur 2. Figur 3 angiver sammenhængen mellem variablene i de to dimensioner, og kan også bruges til at vurdere hvilken information principal komponenterne hovedsageligt bærer. I ovenfor viste tilfælde er dette imidlertid vanskeligt.
I figur 4 er vist det såkaldte biplot hvor både variable og objekter er projiceret ind på de samme to principal komponenter, hvilket svarer til at man lægger figur 2 og figur 3 oven på hinanden. Biplottet kan bruges til at se hvorfor nogle objekter er outliers eller hvad der er den underliggende årsag til at objekterne ligner hinanden. Prøve no. 80.01.05.01 kunne f.eks. være langt fra de andre på grund af højt indhold af jern og sulfat, men det kunne også være lavt indhold af nitrat og ilt (formentligt begge dele). Ovennævnte prøve ligger tæt på gruppen af jern og sulfat (røde triangler, fe og so4) og langt fra gruppen af nitrat og ilt (røde triangler, o2 og no3).
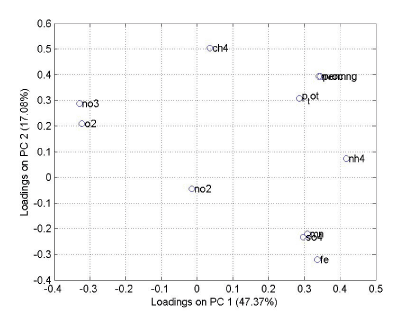
Figur 3 Loading plot.
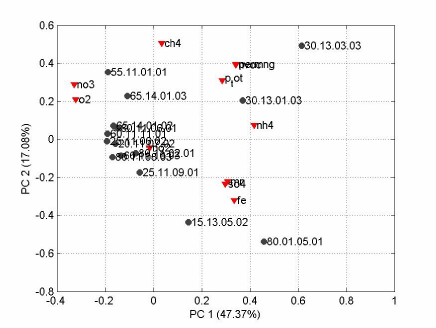
Figur 4 Biplot.
Når man har dannet en god model af en række objekter (boringer med fund), kan det være relevant at undersøge om nye prøver, eller prøver fra en anden population (boringer uden fund) passer ind i modellen, og hvis ikke hvorfor de ikke gør dette. Her kan man bruge biplottet fra figur 4 og projicere de nye prøver ind på dette som vist i figur 5.
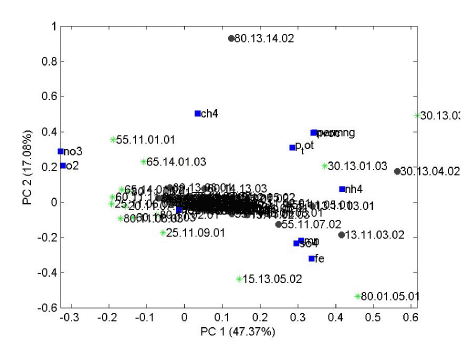
Figur 5 Biplot med projicerede data.
De grønne markeringer viser de objekter der har dannet modellen (boringer med fund), mens de sorte unavngivne viser de projicerede data (boringer uden fund). De blå kvadrater angiver beliggenheden af variablene. I dette tilfælde er det nærliggende at tolke de nye objekter (boringer uden fund) som generelt lave i nitrat og ilt, og høje i jern, sulfat og ammonium. Da der kan være en stor residual værdi for disse prøver er det imidlertid nødvendigt at checke rå data for at få dette bekræftet.
Alle illustrationer kan anvendes på PLS-R metoden også og tolkes tilsvarende.
Cluster analyse
Clusteranalyse kan anvendes på samme datastrukturer som f.eks. PCA, det vil sige der skal være en række prøver, objekter, med en tilhørende række variable, og disse skal være bestemt for alle de objekter der skal indgå i cluster analysen.
Cluster analyse er et velegnet værktøj til på simpel og visuel måde at finde strukturer i datasæt baseret på de indgåede variable, det vil sige at afgøre hvor godt prøverne ligner hinanden, om der er grupperinger og om der er prøver der er afvigende i forhold til disse grupperinger.
I vores tilfælde anvendes clusteranalysen på resultatet fra PCA analysen, det vil sige objekterne projiceret ind i det reducerede variabelrum bestemt af de betydende principal komponenter.
Clusteranalysen foregår ved en parvis beregning af hvor stor forskel der er mellem(afstand der er mellem) forskellige prøver i projektionen nævnt ovenfor. Identiske prøver har afstanden 0. Fremgangsmåden er iterativt efter følgende princip:
- Analysen starter således med afstanden 0, som øges indtil man når afstanden mellem de to prøver der ligner hinanden mest. For disse to prøver, som udgør den første gruppe, udregnes gennemsnitsbeliggenheden som indgår i den videre analyse.
- Dernæst øges afstanden indtil en af følgende hændelser indtræffer:
- En prøve ligger indenfor afstanden til første gruppes gennemsnitsposition. Alle andre afstande er større. Prøven tilknyttes den første gruppe og en ny gennemsnitsposition for gruppen beregnes.
eller - To prøver som ikke er afstandsmæssigt knyttet til den første gruppe ligger med en indbyrdes afstand der er mindre en prøvernes afstand til gruppen. Disse to prøver udgør nu en ny gruppe, hvis gennemsnitsposition udregnes.
eller - Afstanden mellem to grupper (to gruppers gennemsnitspositioner) er nu den korteste indenfor datasættet. De to grupper danner derfor en ny gruppe hvis gennemsnitsposition beregnes.
- En prøve ligger indenfor afstanden til første gruppes gennemsnitsposition. Alle andre afstande er større. Prøven tilknyttes den første gruppe og en ny gennemsnitsposition for gruppen beregnes.
- Processen fortsætter indtil alle prøver og grupper er tilknyttet hinanden med et afstandskriterie.
Fremgangsmåden, der lyder kompliceret, kan illustreres med følgende simple konstruerede eksempel for et todimensionalt datasæt, tabel 1. Man kan ved hjælp af en lineal konstatere gyldigheden af processen:
| Prøve | X (egenskab1) | Y (egenskab2) |
| A | 1 | 1 |
| B | 2 | 1 |
| C | 2 | 2 |
| D | 2 | -1 |
| E | 2 | -3 |
| F | -3 | -3 |
Tabel 1 Tabel over konstrueret simpelt datasæt.
Afstandene mellem prøvernes egenskaber kan illustreres i et XY-plot, figur 6.
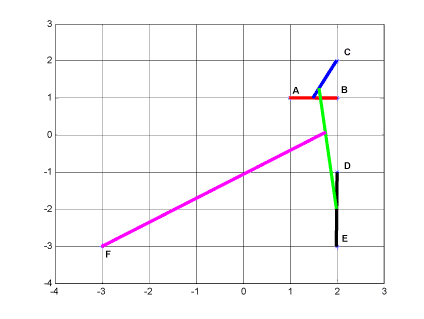
Figur 6 XY plot der viser afstandsberegning for datasættet i tabel 1. De enkelte prøvers egenskaber er angivet ved gridnettets krydspunkter. De farvede linier forbinder de prøver eller beregnede gennemsnitspositoner af prøvernes egenskaber som successivt gennem analysen ligger hinanden nærmest, startende med den røde linie og afsluttende med den lilla.
Fremstillingen af resultatet af clusteranalysen i figur 6 bliver uanvendelig ved multivariate sammenhænge, da man ikke kan visualisere afstande i et multidimensionalt rum. Derfor illustreres sammenhængen af datasættet i tabel 1 i et såkaldt dendogram, figur 7. De farvede linier i XY plottet figur 6 svarer til de farvede linier i dendogrammet figur 7 og illustrerer identiske afstande.
Prøverne (punkterne) A og B ligger (jævnfør ovenstående indledende forklaring) tættest og udgør den første gruppe, afstanden mellem A og B er markeret med rød linie. C ligger tættere på middelværdien af AB end de øvrige punkter og tilknyttes derfor denne gruppe, der nu består af AB og C, markeret med blå linie. Punktet D ligger tættere på E end på middelværdien af ABC, hvorfor DE udgør sin egen gruppe, markeret med sort linie. Gruppen DE ligger tættere på gruppen ABC end på punktet F, der har den største afstand både fra de øvrige pesticider (punkter) og grupper. Grupperne samles derfor i en storgruppe bestående af ABCDE. Afstanden mellem ABC og DE er markeret med grøn linie. Slutteligt findes afstanden fra F til gruppen ABCDE (markeret med magenta linie).
Grafisk kan cluster dendrogrammet tolkes som at AB og C udgør en gruppe der ligner hinanden meget. D og E ligner hinanden noget og ligner gruppen ABC mere end de ligner F, der må betegnes som forskellig fra alle de øvrige.
Metoden kan anvendes med et vilkårligt antal dimensioner af datasæt.
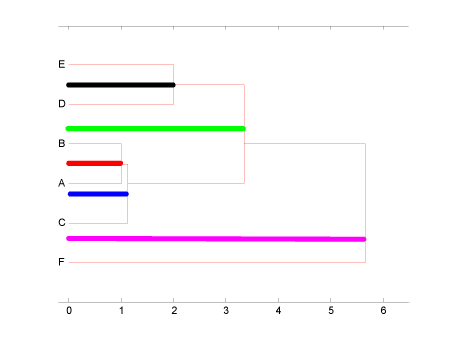
Figur 7 Dendogram. Output fra clusteranalysen. Navnene på prøverne A-F (objekterne) fremgår i venstre side af dendrogrammet. Afstandene mellem (ligheder og forskelle mellem) prøverne er illustreret ved afstanden på x-aksen til den lodrette forbindelseslinie mellem to prøver eller grupper. Dimensionerne er bestemt af længden af de farvede linier som repræsenterer de samme afstande som i figur 6.
Partiel least squares regression (PLS-R)
PLS er en optimering af PCA analysen i forhold til at skabe en model der kan forklare en ukendt variabel (y variablen) ved hjælp af en lineær regression. Udvælgelsen af latente variable udføres, således at der både tages hensyn til beskrivelsen af de variable, der indgår i korrelationen (de uafhængige variable, normalt kaldet x matricen), og evnen til at beskrive den afhængige y variabel efter en veldefineret og standardiseret algoritme. Der henvises til Brereton (1990) eller Esbensen (2002) for en mere uddybende beskrivelse af metoden.
Regressions metoden anvendt i dette projekt kaldes for Partial Least Squares Regression og forkortes PLS-R eller blot PLS. Metoden udmærker sig ved at optimere udvælgelsen af latente variable, sådan at de bedst beskriver både det uafhængige datasæt og det afhængige datasæt. Det betyder at korrelationerne ofte kommer til at bestå af færre latente variable end ved andre metoder og dermed bliver mere simple og lette at fortolke. De latente variable i denne metode kaldes for ”PLS-komponenter” analogt med ”principal komponenter” ved principal component regression og analyse. PLS-regressionsmetoden er begrænset til at beskrive lineære sammenhænge. Dette betyder at rådata i situationer med ikke lineære sammenhænge må transformeres, f.eks. ved en log transformation, for at kunne anvende metoden. Er det ikke muligt af finde en passende transformation, kan det være nødvendigt f.eks. at anvende neurale netværk til at beskrive sammenhængen.
Korrelationerne valideres ved krydsvalidering enten efter ”leave one out” eller segment principperne. Validerings principperne går alle ud på, iterativt og ved forskellige udvælgelses metoder at fjerne variable eller objekter for regressionskorrelationen. Herefter laves ny korrelation og virkningen af udeladelsen undersøges. Krydsvalidering anvendes når det ikke er muligt eller er for dyrt at designe undersøgelserne således at der kan etableres både et læredatasæt og et valideringsdatasæt.
Identifikation af outliers er sket ved at vurdere den enkelte prøves indflydelse (leverage) på korrelationen i sammenhæng med korrelationens (manglende) evne til at prædiktere værdien for prøven (Y standardised residual, fejl på de enkelte y prædiktioner). På figur 8 er vist et plot af ”leverage mod Y std residual”, hvor det ses at prøve 14 er en outlier. Prøve 14 udviser en relativ stor fejl på prædiktionen af prøvens værdi samtidigt med at prøven har høj indflydelse på korrelationen (leverage). Prøve 3 derimod er ikke en outlier, idet prøven på trods af den dårlige prædiktion (høj Y residual) ikke har indflydelse på korrelationen. I sidstnævnte tilfælde ville det være forkert at fjerne prøven, idet denne er med til at beskrive usikkerheden på prædiktionerne ved hjælp af korrelationen.
Outliers opstår sædvanligvis ved at nogle prøver udviser en unormal ”adfærd” for eller imellem de variable der har betydning for korrelationen. Dette svarer til at man i figur 1 har enten meget høj Q residual, altså ikke forklaret variation udenfor modellens forklaringsrum, eller høj T² residual, altså variation indenfor modellens forklaringsrum men udenfor modellens udspændingsbredde.
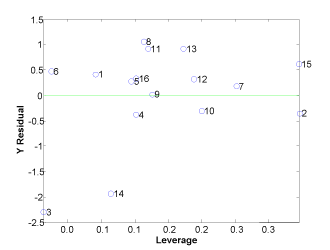
Figur 8 Prøvernes indflydelse (Leverage) på korrelationen mod fejlen i korrelationsevnen ved prædiktion af prøvens værdi (Y Residual). Plottet bruges ved udpegning af outliers i forbindelse med en PLS korrelationsanalyse.
Figur 9 Eksempel på figur der viser korrelationens prædiktionsevne.
Resultaterne fra korrelationsanalyserne illustreres i figurer med korrelationens evne til at prædiktere prøvernes værdi (figur 9), og de uafhængige variables betydning regnet med fortegn for korrelationen (regressionen), se figur 10.
Figur 9 gengiver prædiktionsplottet for korrelationen af et uafhængigt datasæt til en y variabel. På x-aksen vises den målte værdi, mens der på y-aksen vises den korrelerede værdi(den af modellen prædikterede værdi).
Figur 10 Eksempel på figur der viser de uafhængige variables indflydelse på korrelationens evne til prædiktion af de afhængige variable. De tilføjede fremhævelser er forklaret yderligere i teksten herunder.
Figur 10 viser det andet plot, regressionsplottet, der altid angives som resultat fra korrelationsanalyserne. Af regressionsplottet fremgår de uafhængige variables (markeret med grøn cirkel) indflydelse på korrelationen. Regressionsvektorerne (rød cirkel) viser størrelsen af indflydelsen, samt om der er tale om negativ eller positiv regression til den afhængige variabel.
1.4 Statistisk bearbejdning af data fra 2001/2002 indsamlet i forbindelse med undersøgelse af små private vandforsyningsanlæg i Storstrøms Amt
1.4.1 Klassifikation
Belægningen er klassificeret på følgende måde:
- Kun asfalt = 0
- Kun cement=1
- Kun grus og jord = 2
- Kun sten og brosten = 3
- Blandet = 4
Dette er gjort ud fra en overvejelse om, hvor der er størst chance for at der bliver behandlet med ukrudtsmiddel.
Hvor 0 er klassificeret som mindst risiko for udvaskning, mens 4 er størst. Der er tilstræbt en lignende rækkefølge i det følgende.
Hvor der ikke er angivet afstand til septictank, sivebønd, kloak og møding er der indsat 133 meter
Terrænfald bort fra brønd –1, intet fald 0 og mod brønd 1. Er der intet angivet sættes det til 0.
Tilstrømningsrisiko er sat til ikke sandsynlig 0, mulig 1, stor 2. Intet angivet 0.
Forurenet lille 0, mulig 1, stor 2, konstateret 3. Intet angivet 0.
Udtagningssted, Udendørs 0, køkken og bryggers 1, udhus og andet 2, stald 3.
Boring 0, boring i brønd 1 og brønd 2.
Placering have 0, andet og bygning 1, mark og skov 2 og gårdsplads 2.
1.4.2 Notation for prøver
Vandforsyninger der er undersøgt i anden undersøgelse i Storstrøms Amt, hvor der er fundet glyphosat og AMPA over grænseværdien aaX. Vandforsyninger der blev fundet glyphosat og AMPA over grænseværdien i første undersøgelse men ikke i den nye, enten fordi de ikke har villet deltage eller fordi indholdet er faldet under grænseværdien aZ. Vandforsyninger der ikke er fundet glyphosat og AMPA i i første undersøgelse a. Dette gøres for hurtigt at kunne danne sig et overblik over fordelingen i de plot der laves i analysen.
1.4.3 Strategi
Der køres på alle variable der ikke har noget med forurening umiddelbart at gøre. Det vil sige oplysninger om vandforsyningen, dybde til grundvandsspejl etc. og også de uorganiske parametre, der kan fortælle noget om hvilken grundvandstype der er prøvetaget. Derimod bruges pesticid data ikke og data om bakteriologiske parametre, idet det formodes at disse har noget med den almindelige forureningstilstand at gøre, og ikke udgør forklaringsparametre der er relevante i denne undersøgelse.
Der er gennemført en PCA analyse for at undersøge mønstre i rådata og med henblik på at finde ud af om de boringer der er fundet glyphosat og AMPA i er specielle med hensyn til nogen af de øvrige parametre, der er indsamlet i undersøgelsen. I PCA vil der sædvanligvis blive ektraheret mere end tre komponenter og det kan derfor være vanskeligt at afgøre om der eksisterer en underliggende gruppering. Der er derfor kørt en cluster analyse på objekternes koordinater i det reducerede variabelrum, d.v.s. projiceret ind på principal komponterne for at afsløre om der ligger underliggende strukturer, der kan gruppere grupper med fund af glyphosat og AMPA sammen med objekter med særlige karakteristika.
Slutteligt forsøges med en PLS regression at klarlægge om der findes umiddelbare sammenhænge mellem koncentrationen af glyphosat og AMPA og f.eks. uorganiske parametre. Denne regression vil vise om der er anlæg med fund der er mere sårbare end andre baseret på de informationer vi har.
1.4.4 Test 1
Her undersøges alle objekter med oplysninger fra interview skema og med oplysninger om uorganiske parametre.
Ved at tage alle objekter og alle interview data sammen med de uorganiske parametre får en temmelig dårlig model. Der skulle ekstraheres 14 pca for at kunne forklare 80% af variationen i datasættet hvilket bestemt tyder på et ret tilfældigt fordelt datasæt. Cluster analysen på datasættet er vist i nedenstående figur, og det ses tydeligt at objekter der er fundet glyphosat og AMPA i, i sidste analyserunde(aaX) og de det blev fundet i, i forrige runde (aZ) fordeler sig nogenlunde jævnt blandt objekter der hører til den ene eller til den anden gruppering i det totale datasæt.
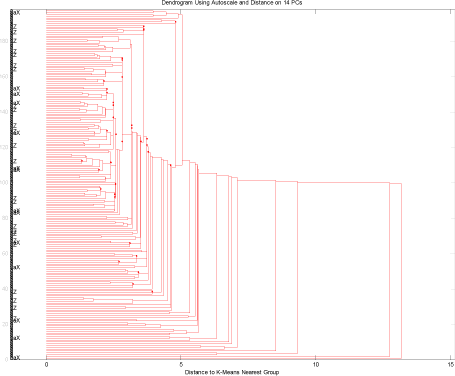
Figur 11 Test af alle prøver fra Storstrøms Amt med alle interview data og uorganiske parametre.
Herefter tages alle variable dog uden uorganiske parametre. Modellen her er noget bedre, idet der her kun skal 8 principale komponenter til at forklare 80% af variationen i datasættet. Dendrogrammet, figur 12, antyder heller ikke her at der er en separation af objekter med fund baseret på interview skemaet.
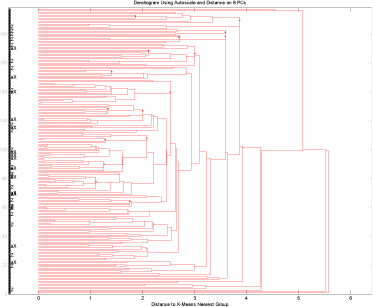
Figur 12 Test af alle prøver fra Storstrøms Amt med kun interview.
Slutteligt testes alle objekter men kun med de uorganiske parametre. Med 7 principal komponenter kan vi forklare 82% af variationen i datasættet. Clusteranalysen, figur 13, viser at de vandforsyninger med fund over grænseværdien heller ikke på det område er specielle, idet de fordeler sig helt jævnt i forhold til alle de undersøgte vandforsyninger.
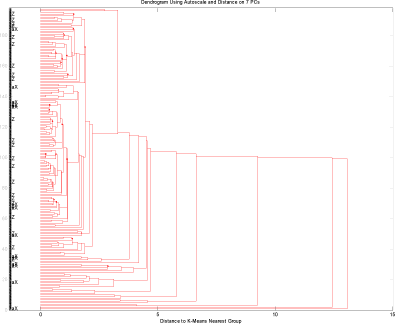
Figur 13 Test af alle prøver fra Storstrøms Amt kun med uorganiske parametre.
1.4.5 Test 2
Ovennævnte mangel på sammenhæng kan skyldes at der sammenlignes prøver fra forskellige anlægstyper. Fund i brønde udgør den største population, derfor testes om der indenfor brøndene kan identificeres egenskaber der udskiller fund gruppen med ikke fund gruppen.
Hvis man kigger på alle data fås en model der er vanskelig at forklare, nogenlunde svarende til fig. 11, og der skal 11 pca til at forklare 81% af variationen i datasættet.
Clusterdiagrammet, figur 14, viser at fund og "ikke fund" fordeler sig tilfældigt i dette datasæt.
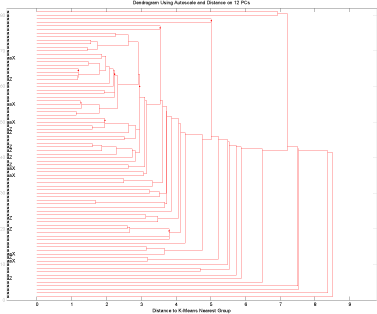
Figur 14 Test af prøver fra brønde fra Storstrøms Amt med alle interview data og uorganiske parametre.
En test af samme prøver fra brønde giver heller ikke nogen klar gruppering af fund gruppen, figur 15.
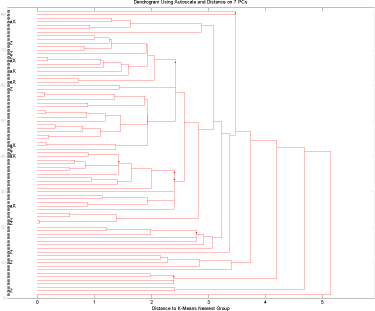
Figur 15 Test af prøver fra brønde fra Storstrøms Amt kun med interview data.
Heri skulle dog kun 7 pc’ere til at forklare godt 80% af variationen, så det er en lidt bedre model. Med lidt god vilje kan man her og i sidste plot finde hovedparten af overskridelserne indenfor en gruppe der er relativt snæver i variation. Ved at kigge på bi-plot, (ikke vist) kan der muligvis peges på en betydning af belægningen omkring brønden, men det er en svag og ikke signifikant indikation.
Tages kun kemidata fås en endnu bedre model. 6 pc’ere kan forklare godt 81% af variationen i datasættet.
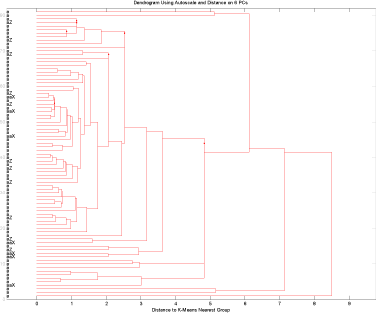
Figur 16 Test af prøver fra brønde fra Storstrøms Amt med uorganiske parametre.
Ved kun at medtage uorganiske parametre blev grupperingen indikeret i figur 15 ikke bekræftet, figur 16.
1.4.6 Test 3
En mangel på sammenhæng mellem brøndene kan skyldes at der er undersøgt anlæg hvorom man i nogle tilfælde ved der har været anvendt glyphosat, anlæg hvor man ved det ikke har været anvendt og endeligt anlæg hvor det er usikkert. Det betyder at anlæg der er følsomme overfor glyphosat anvendelse evt. ikke er forurenet ganske enkelt fordi glyphosat ikke har været anvendt. Test 3 vil derfor teste "ikke fund" gruppen, men kun de anlæg hvor der fra interview undersøgelsen er indikeret at glyphosat har været anvendt samt de anlæg der i 2003 har været fund i.
Test 3 følger test 1 og test 2, dog er der ikke vist resultaterne hvor både kemi data og interview data er medtaget, idet disse altid medførte dårligt forklarede modeller. Der er i alle tilfælde ekstraheret mindst 80% og maksimalt 85% af variationen i datasættet, antallet af principalkomponenter fremgår af figurerne.
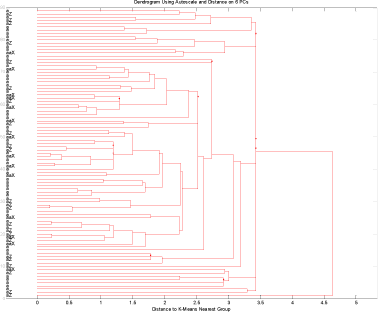
Figur 17 Alle anlæg uden fund men hvor glyphosat har været anvendt sammen med fund gruppen. Kun interview data.
Figur 17 viser at der i det reducerede datasæt ikke er gruppering af fund gruppen i forhold til ikke fund gruppen. Dette billede bekræftes hvis der testes på kemi data, figur 18.
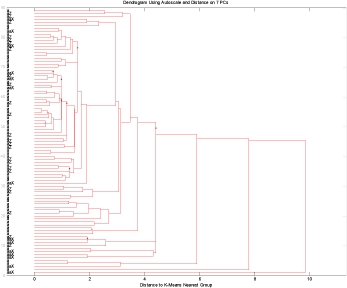
Figur 18 Alle anlæg uden fund men hvor glyphosat har været anvendt sammen med fund gruppen. Kun kemi data.
I lighed med test 2 kan brøndene undersøges separat.
Som det fremgår af figur 19 og figur 20 er der heller ikke blandt brøndene gruppering baseret på de undersøgte variable.
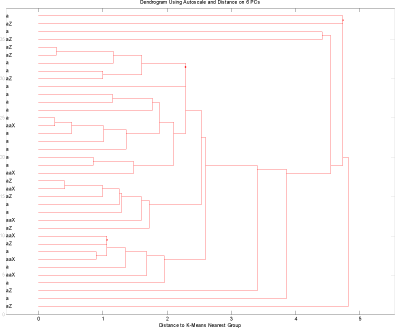
Figur 19 Brønde uden fund, men hvor glyphosat har været anvendt sammen med fund gruppen(brønde). Kun interview data.
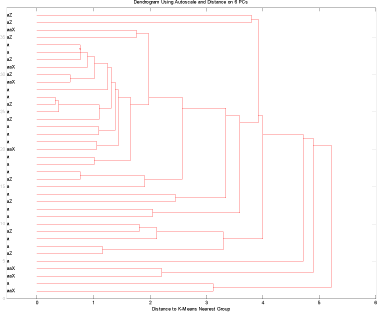
Figur 20 Brønde uden fund men hvor glyphosat har været anvendt sammen med fund gruppen(brønde). Kun kemi data.
1.4.7 Test 4
Blandt fund gruppen vil det være relevant at undersøge om der indenfor denne gruppe er sammenhæng mellem forureningsgraden og interview og kemi data. Dette er gennemført ved at køre en PLS regression hvor sum koncentrationen af glyphosat og AMPA er korreleret til datasættet. En test hvor alle anlægstyper er medtaget gav ikke noget sammenhæng, hvorimod et reduceret objekt sæt med kun brønde gav en god model. Der blev blandt de 24 brønde identificeret 3 outliers, og det resterende datasæt gav en model hvorfra 84% af variationen i koncentrationen kunne forklares.
Modellens evne til at prædiktere koncentrationen er fornuftig, figur 21. Det ses at lave koncentrationer er vanskelige at prædiktere, men i dette koncentrationsinterval må det også forventes at der er en betydelig usikkerhed på målingen, hvorimod de højere værdier rimeligt sikkert kan estimeres.
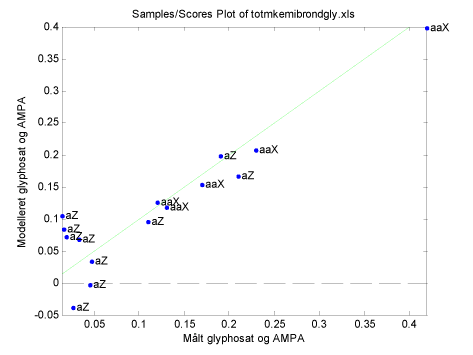
Figur 21 PLS modellens prædiktionsevne. Der er medtaget brønde med fund samt kemidata og interview data.
Variable uden indflydelse på modellen er fjernet. Betydning af variable der er medtaget fremgår af figur 22. Regressionen skal læses med fortegn, det vil sige at negativ regression betyder lavere koncentration og at positiv regression betyder højere koncentration.
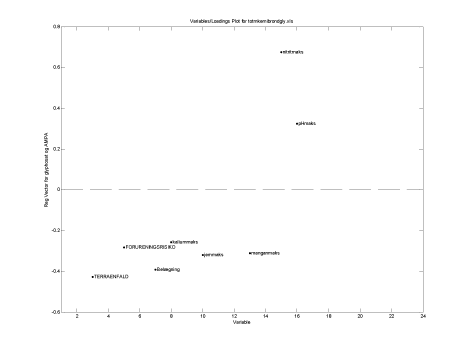
Figur 22 Betydning af variablene på koncentrationen af glyphosat og AMPA i brønde fra Storstrøms amt.
Det er ret overraskende at det man har vurderet som lille forureningsrisiko samt terrænfald væk fra brønd giver anledning til stor risiko giver anledning til forøget risiko. Det er ligeledes overraskende at belægningstypen har den modsatte effekt af hvad der er forudsat.
Med hensyn til kemi data er det ikke overraskende at pH har stor betydning. I Kupa projektet er der undersøgt sammenhængen mellem glyphosats bindingsevne og jordparametre, her havde pH meget stor betydning. Nitrit er relateret til tilstedeværelse af organisk stof (nitratreduktion), mens jern og mangan ofte er relateret til dybden til grundvandet.
1.4.8 Konklusion – oplysninger fra Storstrøms Amt indsamlet i 2001/2002
I PCA testene kunne der ikke med de valgte kombinationsmuligheder og med de anvendte data identificeres grupperinger af fund gruppen i forhold til "ikke fund" gruppen, og dermed kunne der heller ikke peges på egenskaber ved anlæggene eller vandets kemi der kan forklare hvorfor nogle anlæg er forurenet og andre ikke. Dette kan skyldes en række årsager:
- Interview data er upræcise og/eller at der ikke er anvendt samme kriterier for vurderingerne på anlæggene. Det er dog samme interviewer og prøvetager, der har indsamlet alle vandprøver og oplysningerne til det første interviewskema. Ved genbesøget i 2005 blev der ikke fundet forkerte oplysninger i det materiale, der tidligere blev indsamlet. Analysedata indsamlet i 2001 må derfor anses som præcise og sammenlignelige.
- Den ranking der er anvendt i testene er ikke korrekt i forhold til rækkefølgen med hensyn til sårbarhed. Dette er meget sandsynligt og bekræftet i PLS analysen.
- De egenskaber der har betydning for om glyphosat og AMPA udvaskes er ikke identificeret. Dette undersøges i projektets fase 2, idet en nærliggende årsag kunne være geologiske forhold.
- Grunden til at glyphosat og AMPA findes i anlæggene skyldes uhensigtsmæssig adfærd, hvilket kan være endog meget vanskelig at identificere. Dette understøttes også af at der i de anlæg, der i dag stadig er aktive er fundet en langt mindre andel med fund af glyphosat eller AMPA end i de anlæg der ikke i dag indvinder grundvand. Dette kunne tyde på, at ejere til aktive anlæg har ændret adfærd efter den første undersøgelse, hvor der blev fundet glyphosat/AMPA i drikkevandet fra deres anlæg.
Korrelationsanalysen, der viser sårbarheden indenfor gruppen med fund i brønde, indikerer at den måde belægningens betydning vurderes, samt de kriterier der har været anvendt til en vurdering af sårbarheden, herunder også terrænfald, har været forkerte. Dette har givet anledning til en nærmere undersøgelse af disse forhold blandt de brønde, der har haft fund i 2005, hvor der blev indsamlet oplysninger om forholdene omkring de enkelte anlæg. Det var dog ikke muligt at identificere betydende sammenhænge mellem belægning og forhold omkring de enkelte anlæg. De indsamlede oplysninger og foto dokumentation viser at alle de besøgte anlæg har meget varierende belægninger, og belægningstyperne varierede fra staudebed, græsplæne, grus under halvtag, cementdække, perlegrus, jord under træ terrasse, fliser, grus, perlegrus, eller stabil grus over gamle brolægninger og forskellige mellemformer, som f.eks. perlegrus med græs og andre planter.
Endelig tyder korrelationsanalysen på, at der er en betydning fra parametre der har betydning for glyphosat og AMPA’s bindingsevne til jordpartikler samt til grundvandets sammensætning. Disse indikationer er beskrevet i næste afsnit.
1.5 Statistisk bearbejdning af data fra 2005 indsamlet i forbindelse med undersøgelse af anlæg med fund af glyphosat/AMPA i små private vandforsyningsanlæg i Storstrøms Amt
Ved den statistiske bearbejdning af analyseresultater indsamlet i 2005 er der anvendt de vandprøver, hvor der er analyseret for glyphosat, AMPA, BAM og for hovedbestanddele. Desuden er der anvendt andre indsamlede oplysninger som f.eks. vandspejlets beliggenhed i de brønde, boringer og håndboringer, hvorfra vandprøverne er udtaget, samt prøvetype.
Der blev i de første bearbejdninger anvendt sum koncentration for glyphosat + AMPA i alle de analyserede vandprøver med fund, og en lineær regressions model blev forsøgt dannet. Denne havde dog en dårlig forklaringsevne. Tilsvarende viste en cluster analyse ikke nogen logisk udskillelse af grupper for de undersøgte vandprøver.
En sammenligning af vandprøver med fund af AMPA og vandprøver uden fund viste, at der ikke var forskel på de to grupper, hvilket kunne forventes, da det formodentlig er anvendelsen af glyphosat, der er styrende for om der kan genfindes AMPA i de undersøgte vandprøver.
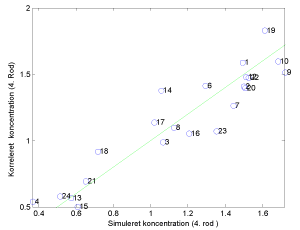
Dernæst blev vandprøver med fund af AMPA testet, og 6 outliers blev fjernet, indtil modellen opnåede en sikkerhed på knap 90%.
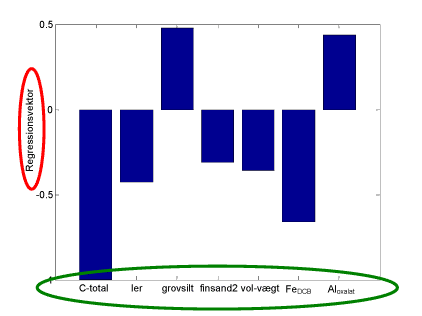
Figur 23 viser, at PLS modellens prædiktionsevne på en rimelig måde er i stand til at forudsige AMPA koncentrationer for 21 ud af 27 vandprøver med fund af AMPA, hvor der er gennemført analyse af hovedbestanddele, mens figur 24 viser betydningen af variablene på AMPA koncentrationen i vandprøver. Variable med lille eller ingen indflydelse i modellen er fjernet, og der er således kun medtaget betydende variable.
Af figur 24 fremgår, at der er en gruppe variable der korrelerer positivt og en gruppe variable der korrelerer negativt - dels findes stigende AMPA koncentrationer ved relativt højt indhold af Na, Cl, Ca, og PO4 og pH, mens AMPA indholdet er lavt ved stigende dybde til vandspejlet i brønde og håndboringer, stigende milliækvivalent og ledningsevne (cond). Dette stemmer godt overens med resultaterne fra håndboringerne og brøndene, der viser, at der hurtigt kan transporteres vand fra overfladen til det højtliggende grundvand og at dette er karakteriseret af højt PO4 indhold, lav ledningsevne, men også at der også kan findes mere dybtliggende grundvand, hvor både klorid og natrium indhold er stort.
AMPA indholdet korrelerer positivt med høje calcium koncentrationer i det højtliggende grundvand, hvilket formodentligt skyldes, at jordbruget anvender kalk som jordforbedrende middel. Den positive sammenhæng mellem PO4 og AMPA stemmer også godt overens med, at der netop findes høje PO4 koncentrationer i de øverste jordlag og at AMPA og PO4 formodentlig følger samme transportveje.
Den negative sammenhæng mellem stigende afstand til grundvandsspejlet og et faldende AMPA indhold stemmer godt overens med at både glyphosat og AMPA koncentrationer falder med stigende dybde.
Den modsatrettede sammenhæng mellem AMPA og henholdsvis Cl og Na på den ene side og ledningsevnen på den anden skyldes, at vandprøverne er præget af hvilke transportveje og hvilken alder de enkelte vandprøver har, og der kan derfor skelnes mellem "tyndt" og "tykt" vand, hvor det tynde vand er regnvand der hurtigt infiltreres til det højtliggende grundvand via makroporer.
En mulig forklaring på sammenhængen mellem et højt klorid indhold og høje AMPA koncentrationer kunne være, at der ved dyrkning af roer kan anvendes gødningstyper med et højt klorid indhold, fordi roer er tolerante overfor høje kloridkoncentrationer. Imidlertid viser figur 25, at anlæggene som bidrager med data til den opstillede model, ikke er koncentreret til Lolland/Falster, hvor den mest intensive roedyrkning finder sted. Dette underbygger således, at det snarere er transportvejene ved infiltration fra overfladen, der er styrende for vandkvaliteten i de vandprøver, hvor der er fundet AMPA.
Det er også bemærkelsesværdigt at indholdet af coliforme bakterier ikke korrelerer med AMPA. Dette underbygger, at de coliforme bakterier er langt mere udbredt i det højtliggende grundvand end tidligere antaget. Desuden korrelerer AMPA negativt med BAM, og der er fundet en sammenhæng mellem lave AMPA og høje BAM koncentrationer. Dette skyldes formodentlig, at BAM forureningen er af ældre dato og at BAM derfor også vil kunne findes i dybere niveauer, selv mange år efter brugen af BAM's moderstof. AMPA's forekomst må formodes at være styret af anvendelsen af glyphosat på tilgrænsende arealer.
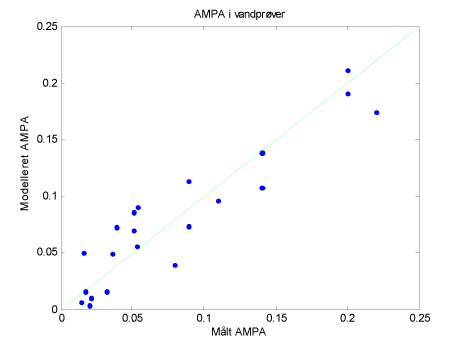
Figur 23 PLS modellens prædiktionsevne. Der er medtaget brønde, anlæg og håndboringer med fund samt kemidata og andre indsamlede data.
Der er også gennemført forskellige test for at undersøge, om der er forskel på om vandprøverne er udtaget fra håndboringer, brønde anlæg, grøfter etc. i relation til uorganiske parametre. Figur 26 viser, at prøvetypen ikke grupperer sig i klare grupper, og at der ikke er forskel på vandprøverne, hvad enten disse er udtaget fra håndboringer i opsprækket moræneler, dræn, brønde, eller fra anlæggene. Dette var også forventeligt, da både brønde og anlæg er i direkte forbindelse med makroporerne i den opsprækkede moræneler, og vandet fra de højtliggende magasiner præger derfor vandkvaliteten i både brønde og anlæg.
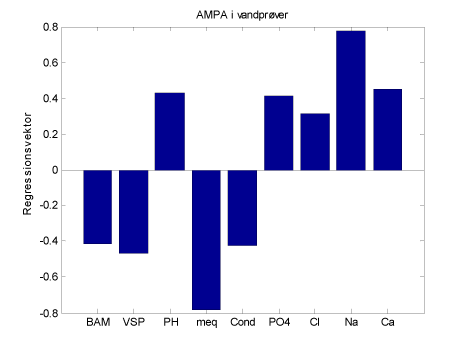
Figur 24 De uafhængige variables indflydelse på korrelationens evne til prædiktion af de afhængige variable. Betydning af variablene på koncentrationen af AMPA i vandprøver fra Storstrøms amt. Ved stigende AMPA koncentrationer ses en god overensstemmelse med f.eks. Na, mens der ved lave AMPA koncentrationer ses en god overensstemmelse med stigende dybde til vandspejlet.
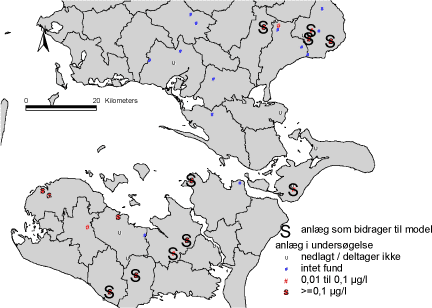
Figur 25 Anlæg som bidrager med data til den opstillede model.
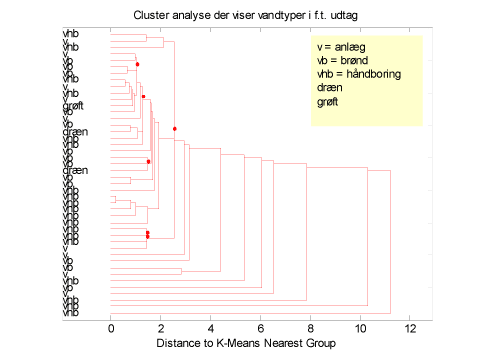
Figur 26 Vandtyper fra forskellige udtag i forhold til hovedbestanddele, AMPA og BAM.
1.6 Konklusion for data indsamlet i 2005
Den gennemførte statistiske viser, at der i det højtliggende grundvand kan skelnes mellem to forskellige vandtyper, som er karakteriseret af hvilken opholdstid vandet har haft i de højtliggende grundvandsmagasiner, og af at det er transporten gennem makroporer, opholdstider og dybden til vandspejlet som er de mest betydende faktorer, når sårbarheden af en AMPA forurening skal bedømmes.
Desuden kunne der ikke skelnes mellem forskellige vandtyper i forhold til, hvor vandprøverne var udtaget. Dette viser, at anlæg der indvinder grundvand fra højtliggende grundvandsmagasiner i ler, vil være præget af en vandkvalitet svarende til vandkvaliteten i makroporer og dræn.
En sammenligning af vandprøver med fund af AMPA og vandprøver uden fund viste, at der ikke var forskel på de to grupper, hvilket kunne forventes, da det formodentlig er anvendelsen af glyphosat, der er styrende for om der kan genfindes AMPA i de undersøgte vandprøver, der alle er udtaget ved anlæg hvor der er fundet enten glyphosat eller AMPA.
Version 1.0 April 2007, © Miljøstyrelsen.